
SEMANA 2 – Medición en epidemiología (31/03)
Paquete dplyr
Si aún no tienes dplyr, instálalo con:
install.packages(«dplyr») # Instalar
library(dplyr) # Cargar
Si usas tidyverse, dplyr ya viene incluido:
install.packages(«tidyverse») # Instalar todo tidyverse
library(tidyverse) # Cargar todos los paquetes

Vamos a cargar una base de datos de R para los ejemplos:
data(mtcars)
Uso del Operador Pipeline (%>%)
Ejemplo sin pipeline (%>%):
data_filtrada <- filter(mtcars, mpg > 20)
data_seleccionada <- select(data_filtrada, mpg, cyl, hp)
data_ordenada <- arrange(data_seleccionada, desc(mpg))
head(data_ordenada)
Ejemplo con pipeline (%>%):

Ejemplos Prácticos con dplyr



Ahora vamos a practicar con la base de datos who
https://drive.google.com/drive/folders/1fFZZHqKBNJcVfp9Jwl-trLkZVsonETt_?usp=drive_link
Guía para practicar 3.2: https://upch-r4pubh.netlify.app/dplyr
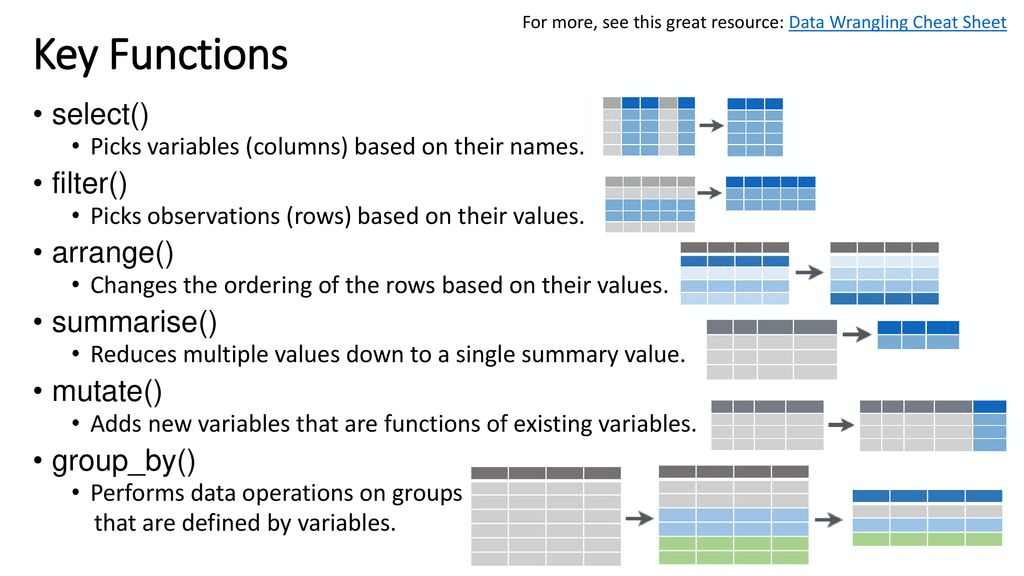
Verbo select()
Verbo filter()
Verbo mutate()
Verbo summarise()
Verbo summarise()
Verbo group_by()
Verbo arrange()
Verbo sample_n()
y terminamos con un trabajo grupal: 3.5 Ejercicios
Paquete tidyr
El paquete tidyr es una de las herramientas clave del tidyverse en R y está diseñado para organizar datos, facilitando su análisis. Su objetivo es ayudarte a transformar tus datos a un formato «ordenado» (tidy data), donde:
Cada variable es una columna.
Cada observación es una fila.
Cada valor está en una celda.
Cargamos el paquete tidyverse:
library(tidyverse)
1. pivot_longer()
Convierte columnas en filas (de formato ancho a largo).
library(tidyr)
datos <- data.frame(
id = 1:2,
enero = c(10, 20),
febrero = c(15, 25)
)
pivot_longer(datos, cols = enero:febrero, names_to = "mes", values_to = "valor")
2. pivot_wider()
Hace lo contrario: convierte filas en columnas (de largo a ancho).
datos_largos <- data.frame(
id = c(1, 1, 2, 2),
mes = c("enero", "febrero", "enero", "febrero"),
valor = c(10, 15, 20, 25)
)
pivot_wider(datos_largos, names_from = mes, values_from = valor)
3. separate()
Divide una columna en varias.
datos <- data.frame(
fecha = c("2024-03-26", "2025-04-01")
)
separate(datos, col = fecha, into = c("año", "mes", "día"), sep = "-")
4. unite()
Combina varias columnas en una sola.
datos <- data.frame(
año = c(2024, 2025),
mes = c("03", "04"),
día = c("26", "01")
)
unite(datos, col = "fecha", c(año, mes, día), sep = "-")
