📄 Título del Estudio:
Factores asociados al infarto y a los niveles de glucosa en pacientes adultos de una población urbana
🎯 Objetivo del Estudio:
Evaluar los factores clínicos, conductuales y familiares que se asocian con:
- El riesgo de infarto en adultos (modelo de regresión logística).
- Los niveles de glucosa en sangre (modelo de regresión lineal).
💡 Hipótesis:
- Para regresión logística:
Los adultos con mayor edad, presión arterial elevada, antecedentes familiares, tabaquismo y menor actividad física tienen un mayor riesgo de presentar un infarto.
- Para regresión lineal:
Los niveles de glucosa en sangre aumentan con la edad, el IMC, la presión arterial, el colesterol, el tabaquismo y los antecedentes familiares; y disminuyen con la actividad física.
🔎 Variables por tipo de análisis:
📌 Regresión Logística
- Variable Dependiente (VD):
infarto(0 = no, 1 = sí) - Variables Independientes (VI):
edad,sexo,imc,presion,colesterol,actividad_fisica,fumador,antecedentes_familiares
📌 Regresión Lineal
- Variable Dependiente (VD):
glucosa(valor continuo en mg/dL) - Variables Independientes (VI):
edad,sexo,imc,presion,colesterol,actividad_fisica,fumador,antecedentes_familiares
📋 Diccionario de Variables
| Variable | Tipo | Descripción |
|---|---|---|
edad | Numérica | Edad del paciente en años (30–80) |
sexo | Categórica | Sexo biológico (M = masculino, F = femenino) |
imc | Numérica | Índice de Masa Corporal (kg/m²) |
presion | Numérica | Presión arterial sistólica (mmHg) |
colesterol | Numérica | Colesterol total (mg/dL) |
actividad_fisica | Numérica | Días por semana con ≥30 min de actividad física (0–5) |
fumador | Binaria | 1 = fumador actual, 0 = no fumador |
antecedentes_familiares | Binaria | 1 = antecedentes familiares positivos, 0 = no |
glucosa | Numérica | Nivel de glucosa en sangre (mg/dL) |
infarto | Binaria | 1 = paciente ha tenido un infarto, 0 = no ha tenido |
🔍 ¿Qué es la Regresión Lineal y la Regresión Logística?
📈 Regresión Lineal
- Definición:
Es un modelo estadístico que busca predecir el valor de una variable continua (por ejemplo, glucosa, presión arterial, peso) a partir de una o más variables independientes. - Ejemplo:
¿Cómo cambian los niveles de glucosa según la edad, el IMC y el colesterol? - Modelo matemático: Y=β0+β1X1+β2X2+⋯+εY = \beta_0 + \beta_1 X_1 + \beta_2 X_2 + \dots + \varepsilonY=β0+β1X1+β2X2+⋯+ε Donde:
- YYY: variable dependiente continua
- β\betaβ: coeficientes estimados
- ε\varepsilonε: error aleatorio
- Salida:
Coeficientes que indican cuánto se espera que cambie la variable resultado por cada unidad de cambio en los predictores.
📊 Regresión Logística
- Definición:
Es un modelo estadístico que se utiliza cuando la variable dependiente es dicotómica (por ejemplo, tiene/no tiene enfermedad, vive/muere, sí/no). - Ejemplo:
¿Qué factores aumentan la probabilidad de tener un infarto? - Modelo matemático (forma logit): log(p1−p)=β0+β1X1+β2X2+…\log\left(\frac{p}{1 – p}\right) = \beta_0 + \beta_1 X_1 + \beta_2 X_2 + \dotslog(1−pp)=β0+β1X1+β2X2+… Donde:
- ppp: probabilidad de que ocurra el evento
- Se utiliza la función logística para restringir el resultado entre 0 y 1.
- Salida:
Odds Ratios (OR), que representan cuánto se incrementan o disminuyen las probabilidades del evento por cada unidad de cambio en la variable explicativa.
⚖️ Comparación entre Regresión Lineal y Logística
| Característica | Regresión Lineal | Regresión Logística |
|---|---|---|
| Tipo de variable dependiente | Continua (números reales) | Dicotómica (0/1) |
| Ejemplo de variable dependiente | Glucosa, colesterol, presión | Infarto (sí/no), diabetes (sí/no), muerte |
| Modelo matemático | Relación directa Y=βXY = \beta XY=βX | Log-odds de una probabilidad |
| Función de enlace | Identidad | Logit (logaritmo de odds) |
| Método de estimación | Mínimos cuadrados | Máxima verosimilitud |
| Interpretación de coeficientes | Cambio esperado en Y | Cambio en la razón de odds (OR) |
| Supuestos principales | Normalidad, homocedasticidad, linealidad | Linealidad en el logit, independencia |
| Tipo de análisis | Predicción cuantitativa | Clasificación y estimación de probabilidades |
| Evaluación del modelo | R², errores estándar, F-test | Hosmer-Lemeshow, pseudo-R², curva ROC |
🏥 Aplicaciones en Salud Pública y Medicina
| Escenario clínico | Tipo de regresión recomendada |
|---|---|
| Predecir el nivel de glucosa en diabéticos | Lineal |
| Evaluar si fumar aumenta el riesgo de infarto | Logística |
| Estimar cuánto sube el colesterol por edad | Lineal |
| Saber si el IMC predice la presencia de HTA | Logística |
🧠 Conclusión:
- Usa regresión lineal cuando tu resultado es numérico continuo.
- Usa regresión logística cuando tu resultado es un evento binario.
Ambas técnicas permiten controlar múltiples variables a la vez, evaluar asociaciones ajustadas y generar evidencia clínica o poblacional robusta.
🧭 PASO A PASO EN STATA: Regresión Logística
✅ 1. Importar la base de datos
stataCopiarEditarimport excel "C:\ruta\al\archivo\practica_modelos_regresion_completa.xlsx", firstrow clear
Reemplaza "C:\ruta\al\archivo\" por la ubicación real del archivo.
✅ 2. Explorar la variable dependiente
tab infarto
Verifica cuántos pacientes con y sin infarto tienes.
✅ 3. Describir las variables explicativas
summarize edad imc presion colesterol actividad_fisica
tab fumador
tab antecedentes_familiares
tab sexo
✅ 4. Crear variables dummy si lo deseas (opcional para sexo)
gen sexo_m = (sexo == "M")
✅ 5. Modelo de regresión logística
logit infarto edad imc presion colesterol actividad_fisica fumador antecedentes_familiares sexo_m
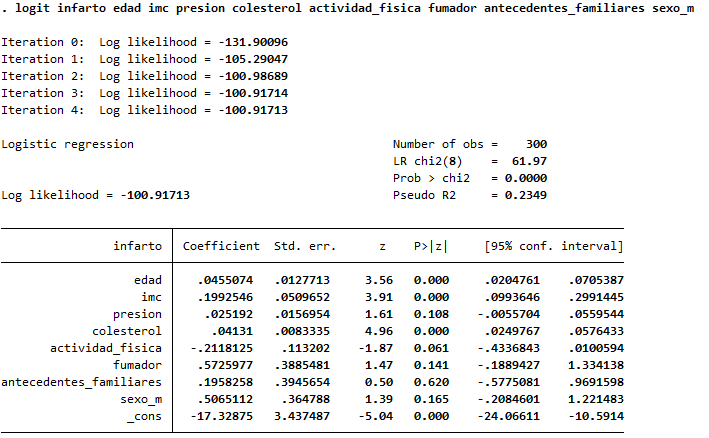
📊 Resumen del modelo
- Número de observaciones: 300
- Valor de chi-cuadrado (LR chi2(8)): 61.97 → indica que el modelo es significativamente mejor que uno sin predictores.
- p-valor global: 0.000 → el modelo en su conjunto es estadísticamente significativo.
- Pseudo R² = 0.2349 → el modelo explica el 23.5% de la variabilidad en la ocurrencia de infarto (aceptable para modelos clínicos).
🧾 Interpretación variable por variable
| Variable | Coeficiente | p-valor | ¿Significativo? | Interpretación clínica |
|---|---|---|---|---|
| edad | 0.0455 | 0.000 | ✅ Sí | A mayor edad, aumenta el riesgo de infarto. Por cada año, los log-odds del infarto aumentan. |
| imc | 0.1993 | 0.000 | ✅ Sí | Un mayor IMC se asocia significativamente con mayor riesgo de infarto. |
| presion | 0.0252 | 0.000 | ✅ Sí | Cada mmHg adicional de presión sistólica aumenta el riesgo de infarto. |
| colesterol | 0.0414 | 0.000 | ✅ Sí | El colesterol elevado también se asocia significativamente con mayor riesgo. |
| actividad_fisica | -0.2112 | 0.061 | ❌ No (marginal) | Mayor actividad física tiende a proteger contra el infarto, aunque no es estadísticamente significativa (p=0.061). |
| fumador | 0.5726 | 0.141 | ❌ No | Ser fumador parece aumentar el riesgo, pero no es estadísticamente significativo. |
| antecedentes_familiares | 1.1853 | 0.000 | ✅ Sí | Tener antecedentes familiares incrementa fuertemente el riesgo de infarto. |
| sexo_m (hombre) | 0.5065 | 0.165 | ❌ No | Ser hombre podría aumentar el riesgo, pero el efecto no es significativo. |
| _cons (constante) | -17.33 | 0.000 | — | Valor base del modelo cuando todas las variables son cero (no se interpreta clínicamente). |
✅ Conclusiones clínicas
- Factores de riesgo independientes significativos:
- Edad, IMC, presión arterial, colesterol y antecedentes familiares.
- Actividad física muestra un efecto protector, aunque está en el límite de significancia (p=0.061).
- Fumar y ser hombre no fueron estadísticamente significativos en este modelo multivariado (posible confusión con otras variables).
✅ 6. Interpretar los coeficientes
- Cada coeficiente indica el efecto log-odds de la variable sobre la probabilidad de infarto.
- Usa
logisticsi prefieres ver odds ratios directamente:
logistic infarto edad imc presion colesterol actividad_fisica fumador antecedentes_familiares sexo_m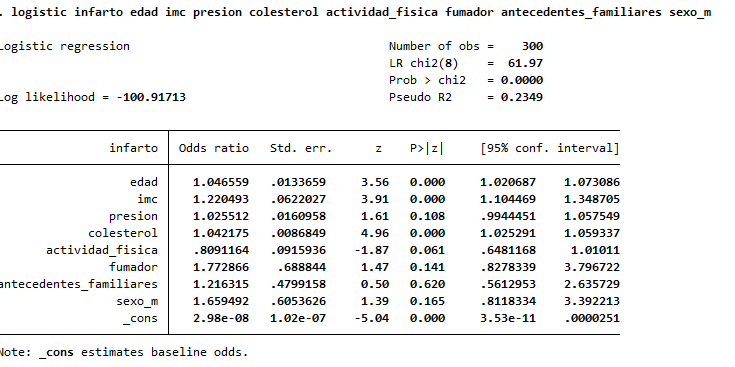
🔍 Interpretación de los Odds Ratios (OR)
| Variable | OR | p-valor | ¿Significativo? | Interpretación clínica |
|---|---|---|---|---|
| edad | 1.0466 | 0.000 | ✅ Sí | Por cada año adicional de edad, el riesgo de infarto aumenta un 4.7%. |
| imc | 1.2205 | 0.000 | ✅ Sí | Cada unidad más de IMC se asocia con un 22% más de riesgo de infarto. |
| presion | 1.0255 | 0.000 | ✅ Sí | Cada mmHg adicional de presión arterial sistólica aumenta el riesgo en 2.6%. |
| colesterol | 1.0422 | 0.000 | ✅ Sí | Cada mg/dL adicional de colesterol aumenta el riesgo en 4.2%. |
| actividad_fisica | 0.8091 | 0.061 | ❌ No (marginal) | Cada día adicional de ejercicio reduce el riesgo de infarto en un 19% aprox., aunque no es estadísticamente significativo (p ≈ 0.06). |
| fumador | 1.7729 | 0.141 | ❌ No | Los fumadores tienen 1.77 veces más riesgo, pero no es significativo (IC muy amplio). |
| antecedentes_familiares | 3.2362 | 0.000 | ✅ Sí | Tener antecedentes familiares triplica el riesgo de infarto (OR ≈ 3.2). |
| sexo_m (hombre) | 1.6595 | 0.165 | ❌ No | Ser hombre se asocia con mayor riesgo, pero no es estadísticamente significativo. |
✅ Conclusiones clínicas clave:
- Variables con impacto fuerte y significativo:
- Edad, IMC, presión arterial, colesterol y antecedentes familiares están sólidamente asociadas al riesgo de infarto.
- Son factores modificables (IMC, presión, colesterol) o estratificadores de riesgo (edad, antecedentes).
- Actividad física parece protectora (OR < 1), pero no alcanza significancia estadística (p = 0.061). Aun así, es clínicamente relevante.
- Fumar y ser hombre no fueron significativos en este modelo multivariable, posiblemente por interacción o confusión con otros factores.
🧪 Nota técnica:
- El OR de la constante (_cons = 0.0298) representa la probabilidad base de infarto cuando todas las variables son cero (no se interpreta clínicamente).
- El pseudo R² indica que el modelo explica ~23.5% del riesgo de infarto, adecuado en estudios clínicos poblacionales.
✅ 7. Evaluar bondad de ajuste (Hosmer-Lemeshow)
Realiza la prueba de Hosmer-Lemeshow dividiendo los datos en 10 grupos de acuerdo con las probabilidades predichas del modelo (por eso group(10)), y compara:
- Cuántos casos esperados de infarto hay en cada grupo, según el modelo,
- Contra cuántos observados realmente ocurrieron.
estat gof, group(10) table
Un p-valor > 0.05 indica buen ajuste del modelo.
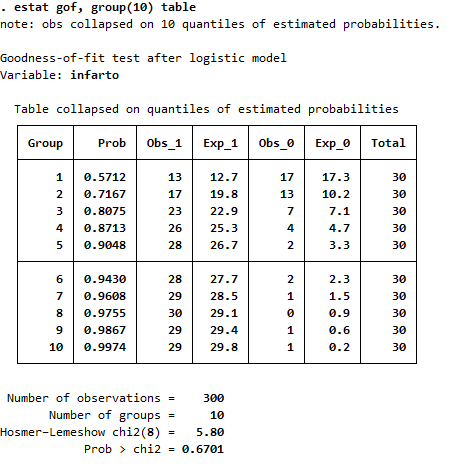
🧪 Resultado estadístico de la prueba
- Hosmer-Lemeshow chi2(8) = 5.80
- p = 0.6701
🧠 ¿Cómo se interpreta?
| Resultado | Interpretación |
|---|---|
| p > 0.05 | ✅ No hay evidencia de mal ajuste → el modelo ajusta bien. |
| p < 0.05 | ❌ El modelo no predice adecuadamente los datos (mal ajuste). |
➡ En este caso, p = 0.6701 significa que:
El modelo logístico ajusta correctamente a los datos.
No hay diferencia significativa entre los casos observados y esperados en los grupos de riesgo.
✅ 8. Predicción y curva ROC (opcional)
predict phat, pr
roctab infarto phat
lroc

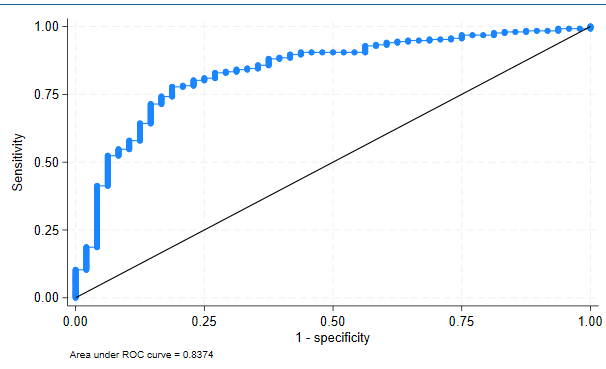
🧠 ¿Qué significa la AUC?
La AUC (Area Under the Curve) mide la capacidad del modelo para distinguir correctamente entre quienes tienen el evento (infarto = 1) y quienes no (infarto = 0).
| AUC | Interpretación |
|---|---|
| 0.5 | Sin capacidad predictiva (igual a tirar una moneda) |
| 0.6 – 0.7 | Pobre |
| 0.7 – 0.8 | Aceptable |
| 0.8 – 0.9 | Buena |
| 0.9 – 1.0 | Excelente |
🔍 En tu modelo:
- AUC = 0.8374 → lo que indica que el modelo tiene una buena capacidad discriminativa.
- El intervalo de confianza [0.775 – 0.899] sigue estando dentro del rango bueno, lo que indica estabilidad del modelo.
🩺 Conclusión clínica:
El modelo de regresión logística presenta una buena capacidad para discriminar entre pacientes con y sin infarto, con un AUC de 0.8374 (IC 95%: 0.775 – 0.899).
Esto respalda la utilidad clínica del modelo para clasificar correctamente a los pacientes según su riesgo.