
🔹 BLOQUE 1: Fundamentos de la Vigilancia Epidemiológica
- Definición e importancia de la vigilancia.
- Tipos de vigilancia: activa, pasiva, centinela, sindrómica.
- Rol de la vigilancia en la salud pública y control de enfermedades.
- Ejemplos de sistemas de vigilancia nacionales e internacionales.
📘 1. Definición e Importancia de la Vigilancia
Definición:
La vigilancia epidemiológica es la recolección sistemática, continua y oportuna de datos sobre eventos de salud, su análisis e interpretación, y la diseminación de esta información para orientar acciones de salud pública
Importancia:
- Detecta brotes de enfermedades (ej. COVID-19, dengue).
- Orienta decisiones para prevenir y controlar enfermedades.
- Identifica poblaciones en riesgo.
- Evalúa el impacto de intervenciones de salud pública.
📌 La vigilancia es el “pulso” de la salud pública.
🧭 2. Tipos de Vigilancia
- Vigilancia pasiva:
- Fuente: Reportes rutinarios de instituciones de salud.
- Bajo costo, pero depende de la iniciativa del personal.
- Ejemplo: Notificación obligatoria de tuberculosis.
- Vigilancia activa:
- Requiere búsqueda activa por parte del personal de salud.
- Más costosa, pero más completa.
- Ejemplo: Estudios especiales durante una epidemia.
- Vigilancia centinela:
- Se usan sitios seleccionados (hospitales, clínicas) para obtener datos de alta calidad.
- Útil para monitorear tendencias.
- Vigilancia sindrómica:
- Se basa en síntomas o síndromes, no en diagnósticos confirmados.
- Rápida detección de brotes, incluso antes de confirmación de laboratorio.
- Ejemplo: vigilancia por fiebre y tos durante brotes respiratorios.
🩺 3. Rol de la Vigilancia en Salud Pública y Control de Enfermedades
- Identifica nuevos problemas de salud (emergentes o reemergentes).
- Monitorea tendencias temporales y espaciales.
- Informa políticas públicas (vacunación, cuarentenas, campañas).
- Evalúa programas de prevención y control.
- Guía la asignación de recursos (humanos, financieros, logísticos).
🌍 4. Ejemplos de Sistemas de Vigilancia
📌 Nacionales:
- CDC (EE. UU.):
- National Notifiable Diseases Surveillance System (NNDSS).
- Behavioral Risk Factor Surveillance System (BRFSS).
- MINSA (Perú):
- SIVE – Sistema de Vigilancia Epidemiológica.
- SINADEF – Vigilancia de mortalidad.
🌐 Internacionales:
- OMS – World Health Organization:
- Sistema de Alerta y Respuesta ante Epidemias (EWARN).
- GOARN – Red Mundial de Alerta y Respuesta ante Brotes.
- ECDC – European Centre for Disease Prevention and Control.
📌 Actividad sugerida (ABP):
Caso problema:
Un hospital reporta un aumento de casos de meningitis en adolescentes en un distrito urbano. ¿Qué tipo de vigilancia se debería reforzar? ¿Cómo se evaluaría la magnitud del problema?
🔹 BLOQUE 2: Historia Natural de la Enfermedad
- Etapas: susceptibilidad, preclínica, clínica y recuperación/muerte.
- Prevención primaria, secundaria y terciaria.
- Transición epidemiológica y determinantes de la salud.
📘 1. Concepto de Historia Natural de la Enfermedad
La historia natural de la enfermedad describe la evolución de una condición de salud desde su inicio (en una persona susceptible) hasta su resolución (recuperación, discapacidad o muerte), sin intervención médica.
Este concepto es clave para:
- Comprender el curso biológico de las enfermedades.
- Determinar cuándo y cómo intervenir eficazmente.
- Planificar estrategias preventivas y de diagnóstico oportuno.
⏳ 2. Etapas de la Historia Natural
🟡 2.1. Etapa de susceptibilidad
- El individuo aún no ha contraído la enfermedad, pero tiene factores de riesgo que aumentan su probabilidad de enfermar.
- Ejemplo: una persona que fuma, sin síntomas, es susceptible a desarrollar EPOC o cáncer de pulmón.
🟠 2.2. Etapa preclínica
- La enfermedad ya está presente, pero no hay signos ni síntomas detectables.
- Puede haber alteraciones fisiológicas o pruebas positivas.
- Ejemplo: infección por VIH en fase aguda, sin síntomas.
🔴 2.3. Etapa clínica
- Aparecen síntomas y signos detectables.
- Diagnóstico posible por métodos clínicos o laboratoriales.
- Ejemplo: fiebre, tos y dificultad respiratoria en neumonía.
⚫ 2.4. Etapa de resolución
- La enfermedad sigue su curso hacia:
- Recuperación completa.
- Estado crónico o discapacidad.
- Muerte.
🛡️ 3. Prevención: Niveles y Estrategias
🟩 3.1. Prevención primaria
- Objetivo: evitar la aparición de la enfermedad.
- Se aplica en la etapa de susceptibilidad.
- Estrategias: vacunación, cambios en el estilo de vida, legislación sanitaria.
- Ejemplo: uso de repelentes para evitar dengue.
🟨 3.2. Prevención secundaria
- Objetivo: detectar precozmente y tratar la enfermedad para limitar su progresión.
- Se aplica en la etapa preclínica o clínica temprana.
- Estrategias: tamizaje, diagnóstico precoz, aislamiento.
- Ejemplo: prueba de Papanicolaou para detectar lesiones precancerosas.
🟥 3.3. Prevención terciaria
- Objetivo: reducir las complicaciones o secuelas de una enfermedad establecida.
- Se aplica en la etapa clínica avanzada o de resolución.
- Estrategias: rehabilitación, seguimiento, control de síntomas.
- Ejemplo: fisioterapia post-ACV o control de la glicemia en diabetes para evitar complicaciones.
🌍 4. Transición Epidemiológica
La transición epidemiológica es un proceso a nivel poblacional donde cambian los principales problemas de salud:
| Fase | Características principales |
|---|---|
| Transición inicial | Predominan enfermedades infecciosas, desnutrición y mortalidad infantil. |
| Transición intermedia | Disminuyen infecciones, aumentan enfermedades crónicas. |
| Transición avanzada | Predominan enfermedades crónicas, degenerativas y causas externas (accidentes, violencia). |
📌 Esto ocurre debido a mejoras sanitarias, acceso a atención médica, cambios en estilos de vida y envejecimiento poblacional.
🧠 5. Determinantes Sociales de la Salud
Son factores sociales, económicos, culturales y ambientales que influyen en el riesgo de enfermar o morir:
- Nivel de educación.
- Ingreso económico.
- Acceso a servicios de salud.
- Vivienda y saneamiento.
- Género, etnia y entorno laboral.
🌱 Comprender estos factores permite diseñar intervenciones más equitativas y efectivas.
🎓 Actividades sugeridas
💬 Discusión ABP:
Caso problema:
«Una paciente de 58 años con obesidad y diabetes tipo 2 no controlada consulta por visión borrosa y dolor en los pies. ¿En qué etapa se encuentra? ¿Qué intervenciones se pueden aplicar en los distintos niveles de prevención?»
📊 Actividad práctica:
- Crear una línea de tiempo o mapa conceptual de la historia natural de la enfermedad para:
- Tuberculosis
- Diabetes tipo 2
- Cáncer de cuello uterino
🔹 BLOQUE 3: Medidas de Morbilidad
- Incidencia acumulada y tasa de incidencia.
- Prevalencia puntual y de período.
- Diferencias entre incidencia y prevalencia.
- Aplicación en estudios clínicos y poblacionales.
📘 1. ¿Qué es la morbilidad?
La morbilidad se refiere a la ocurrencia de enfermedades, condiciones o eventos de salud en una población.
👉 Medir la morbilidad es esencial para:
- Cuantificar el riesgo de enfermar.
- Comparar poblaciones.
- Evaluar el impacto de programas preventivos.
- Diseñar políticas públicas basadas en evidencia.
📊 2. Incidencia
🔹 2.1. Incidencia acumulada (IA)
Definición:
Proporción de individuos sanos que desarrollan una enfermedad durante un período específico.

Características:
- Es una proporción.
- Requiere seguimiento.
- Ideal para cohortes o estudios longitudinales.
🧪 Ejemplo:
En un estudio de 100 personas sin diabetes al inicio, 5 desarrollan diabetes en 1 año.
→ IA = 5 / 100 = 5%
🔹 2.2. Tasa de incidencia (TI)
Definición:
Número de nuevos casos dividido entre el tiempo total en riesgo (persona-tiempo).

Características:
- Refleja velocidad de aparición.
- Más precisa en poblaciones con entrada/salida variable.
- Útil cuando el seguimiento es desigual o hay censura.
🧪 Ejemplo:
Si en un estudio se acumulan 200 personas-año y se observan 10 nuevos casos,
→ TI = 10 / 200 = 0.05 casos/persona-año
🔍 3. Prevalencia
🔸 3.1. Prevalencia puntual
Definición:
Proporción de personas con la enfermedad en un punto específico del tiempo.

🧪 Ejemplo:
Si 15 de 200 personas tienen hipertensión el 1 de enero,
→ Prevalencia = 15 / 200 = 7.5%
🔸 3.2. Prevalencia de período
Definición:
Proporción de personas que tuvieron la enfermedad en cualquier momento durante un período.
- Incluye casos existentes y nuevos.
🧪 Ejemplo:
Si 30 personas tuvieron COVID-19 en algún momento entre enero y junio, en una población de 300,
→ Prevalencia de período = 30 / 300 = 10%
🔄 4. Diferencias clave: Incidencia vs Prevalencia
| Característica | Incidencia | Prevalencia |
|---|---|---|
| ¿Qué mide? | Nuevos casos | Casos existentes |
| Tiempo | Requiere periodo definido | Punto o periodo específico |
| Tipo de estudio | Cohortes, longitudinales | Transversales |
| Útil para | Causas, riesgo, etiología | Carga de enfermedad, planificación |
| Afectada por | Duración y tasa de curación/muerte | Frecuencia y duración de la enfermedad |
📌 Relación conceptual: Prevalencia≈Incidencia×Duracioˊn\text{Prevalencia} \approx \text{Incidencia} \times \text{Duración}Prevalencia≈Incidencia×Duracioˊn
🏥 5. Aplicación en estudios clínicos y poblacionales
✅ Estudios clínicos:
- Incidencia se usa para calcular el efecto de una intervención (Ej: vacuna, fármaco).
- Permite comparar riesgo entre grupos expuestos y no expuestos.
✅ Estudios poblacionales:
- Prevalencia se usa en encuestas de salud para estimar carga de enfermedad.
- Es útil para planificar servicios y recursos de salud (ej: demanda de tratamiento).
🧠 Ejemplos:
- Encuesta Nacional de Demografía y Salud (ENDES – Perú): prevalencia de anemia en gestantes.
- Ensayo clínico: incidencia de eventos cardiovasculares con o sin tratamiento antihipertensivo.
🎓 Actividades sugeridas
💬 Discusión ABP:
Caso problema:
«En una población de 500 personas, 25 tienen hipertensión y 10 casos nuevos se diagnostican en un año. ¿Cuál es la prevalencia al inicio, la incidencia acumulada y qué decisiones tomarías como epidemiólogo?»
📊 Práctica en R / Stata (opcional):
- Crear una tabla con variables: ID, edad, sexo, fecha de diagnóstico.
- Calcular incidencia acumulada con
summarize()omutate(). - Calcular prevalencia usando
table()oprop.table().
🔹 BLOQUE 4: Medidas de Mortalidad
- Tasa de mortalidad general y específica (edad, causa, grupo).
- Mortalidad proporcional y tasa de letalidad.
- Limitaciones e interpretaciones según contexto.
🔹 BLOQUE 4: Medidas de Mortalidad
⚰️ 1. ¿Qué es la mortalidad?
La mortalidad se refiere al número de muertes que ocurren en una población durante un periodo de tiempo determinado. Es uno de los indicadores más usados para evaluar el estado de salud de una comunidad y la severidad de las enfermedades.
Se expresa generalmente como tasas que permiten comparar poblaciones de diferentes tamaños.
📊 2. Tasa de Mortalidad General
Definición:
Número total de muertes por todas las causas en una población durante un periodo (usualmente un año), por cada 1,000 o 100,000 habitantes.

🧪 Ejemplo:
Si en una ciudad de 500,000 habitantes ocurren 4,000 muertes en un año:
→ Tasa = (4,000 / 500,000) × 100,000 = 800 por 100,000 habitantes
🔍 3. Tasas de Mortalidad Específica
Se enfocan en subgrupos poblacionales o causas específicas.
🧓 Por edad:
- Mortalidad infantil, neonatal, en mayores de 65 años.
🧬 Por causa:
- Mortalidad por cáncer, enfermedades cardiovasculares, accidentes.
👤 Por grupo:
- Sexo, etnia, ocupación, región geográfica.

📌 Son muy útiles para identificar poblaciones de riesgo.
📈 4. Mortalidad Proporcional
Definición:
Proporción de todas las muertes que se deben a una causa específica.
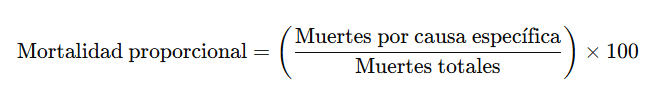
🧪 Ejemplo:
Si hubo 1000 muertes y 250 fueron por ECV → Mortalidad proporcional = 25%
🔔 No mide riesgo, pero indica carga relativa de una enfermedad.
🧪 5. Tasa de Letalidad
Definición:
Proporción de personas con una enfermedad que fallecen por esa causa en un periodo.

🧪 Ejemplo:
De 100 casos de tétanos, 60 mueren → Letalidad = 60%
📌 Útil para medir la gravedad de una enfermedad.
⚠️ 6. Limitaciones e Interpretaciones según Contexto
| Medida | Limitación | Consideración |
|---|---|---|
| Mortalidad general | No distingue causa ni grupo | Útil para comparaciones amplias |
| Mortalidad específica | Requiere datos confiables por grupo | Útil para focalizar intervenciones |
| Mortalidad proporcional | No refleja riesgo | Solo muestra peso relativo |
| Letalidad | Depende de diagnóstico oportuno | Puede sobrestimar si hay subregistro |
🔍 Ejemplo contextual:
Una alta letalidad en un hospital puede reflejar casos más graves (no necesariamente peor atención).
Una tasa de mortalidad baja en un país joven no significa que las enfermedades sean menos letales.
🎓 Actividades sugeridas
💬 Discusión ABP:
Caso:
«En una región con alta mortalidad por enfermedades respiratorias, se quiere priorizar recursos. ¿Qué medida usarías para evaluar el riesgo? ¿Cuál para evaluar la carga? ¿Cuál para medir la gravedad?»
🔹 BLOQUE 5: Comparación de Mortalidad entre Poblaciones
- Diferencia entre tasas crudas y ajustadas.
- Métodos de estandarización: directa e indirecta.
- Uso de población estándar.
- Ejemplos comparativos reales (ej. COVID-19, cáncer).
🔹 BLOQUE 5: Comparación de Mortalidad entre Poblaciones
📊 1. Introducción a la Comparación de Mortalidad
Comparar tasas de mortalidad entre diferentes poblaciones puede resultar engañoso debido a factores demográficos (edad, sexo, estructura poblacional). Para lograr comparaciones justas, es necesario ajustar las tasas usando métodos estadísticos.
⚖️ 2. Diferencia entre Tasas Crudas y Ajustadas
📉 Tasa Cruda de Mortalidad
- Refleja el número total de muertes en una población, sin considerar diferencias demográficas.
- Fórmula:

Ejemplo:
- En un país A con 1,000 muertes en 100,000 habitantes:
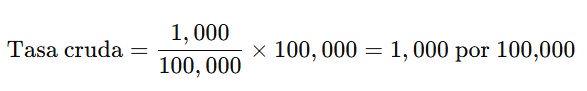
📊 Tasa Ajustada de Mortalidad
- Corrige las diferencias en la estructura de edad (u otros factores) para hacer comparaciones más justas.
- Evita sesgos cuando las poblaciones tienen distribuciones etarias distintas.
Ejemplo:
- La tasa cruda en un país envejecido puede ser mayor que en un país joven, aunque el riesgo individual no sea mayor.
📏 3. Métodos de Estandarización
🧮 3.1. Estandarización Directa
- Se calcula una tasa ajustada usando una población estándar.
- Ideal cuando se tienen tasas específicas por grupo etario.
Pasos:
- Calcular tasas específicas por grupo de edad en cada población.
- Aplicar estas tasas a una población estándar (ej.: población mundial).
- Sumar los resultados para obtener la tasa ajustada.
Ejemplo:
- País A:
- Grupo 20-40 años: 50 muertes / 10,000 personas
- Grupo 40-60 años: 100 muertes / 5,000 personas
- Aplicando a población estándar:
- Tasa ajustada = (50 × 0.6) + (100 × 0.4) = 70 muertes estandarizadas
🧮 3.2. Estandarización Indirecta
- Se usa cuando no se tienen tasas específicas en una población pequeña o con datos incompletos.
- Se obtiene un índice de mortalidad estandarizado (IME) comparando muertes observadas con esperadas.
Fórmula:
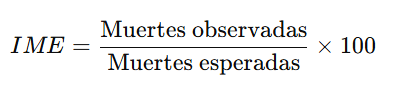
Ejemplo:
- Un hospital reporta 50 muertes por cáncer, pero según la tasa general debería tener 40:
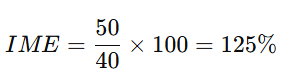
→ Mortalidad 25% mayor a la esperada.
🌍 4. Uso de Población Estándar
¿Por qué es importante?
- Permite comparar tasas entre regiones o países sin que la estructura etaria sesgue los resultados.
- Usualmente se utilizan estándares como:
- Población mundial (OMS).
- Población de EE. UU. (CDC).
- Población europea (ECDC).
Ejemplo:
Durante la pandemia de COVID-19, países europeos mostraron tasas crudas más altas que algunos países latinoamericanos debido a la alta proporción de adultos mayores. Al ajustar, las diferencias disminuyeron, mostrando que el riesgo no era necesariamente mayor, sino que la estructura etaria influía.
💡 5. Ejemplos Comparativos Reales
📌 Caso 1: Mortalidad por COVID-19 (Países A y B)
- País A (envejecido): Tasa cruda de mortalidad: 1,200 por 100,000.
- País B (joven): Tasa cruda de mortalidad: 300 por 100,000.
- Tras ajuste, la tasa ajustada de ambos países fue similar, indicando que la estructura etaria influyó en la tasa cruda.
📌 Caso 2: Mortalidad por Cáncer (Región Urbana vs Rural)
- Mortalidad cruda es más alta en la región urbana.
- Tras ajuste por edad, la tasa de mortalidad en la región rural es mayor debido a una mayor proporción de adultos mayores.
📝 6. Limitaciones de los Métodos de Estandarización
| Método | Ventajas | Desventajas |
|---|---|---|
| Directa | Más precisa si hay datos específicos | Requiere datos detallados |
| Indirecta | Útil para poblaciones pequeñas | Menos precisa si la población estándar no representa bien la población de estudio |
🔔 La selección del método depende de la calidad y disponibilidad de los datos.
🎓 Actividades sugeridas
💬 Discusión ABP:
Caso:
«Dos hospitales presentan tasas crudas de mortalidad diferentes para neumonía. Sin embargo, uno atiende mayor cantidad de pacientes mayores de 80 años. ¿Qué método de ajuste usarías y por qué?»
🔹 BLOQUE 6: Medidas de Impacto en Salud Pública
- Años de vida perdidos (AVP).
- Años de vida ajustados por discapacidad (AVAD o DALYs).
- Esperanza de vida saludable.
- Evaluación del peso de las enfermedades en la población.
🔹 BLOQUE 6: Medidas de Impacto en Salud Pública
🌍 1. ¿Qué son las medidas de impacto en salud pública?
Las medidas de impacto cuantifican la carga que las enfermedades, discapacidades y muertes representan en una población. Permiten priorizar problemas de salud y evaluar el efecto de intervenciones sanitarias.
📏 2. Años de Vida Perdidos (AVP)
📘 Definición:
Los Años de Vida Perdidos (AVP) miden el impacto de las muertes prematuras en la población. Indican cuántos años de vida se pierden debido a fallecimientos ocurridos antes de una edad estándar (generalmente la esperanza de vida).
🧮 Fórmula:
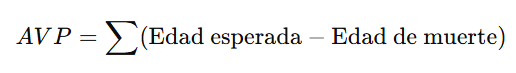
🌟 Ejemplo:
Si la esperanza de vida es 80 años y una persona fallece a los 50 años, el AVP es:
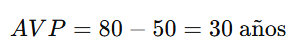
Si en una comunidad hubo 5 muertes prematuras con los siguientes años perdidos: 30, 20, 25, 15, 40:
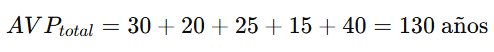
💡 Utilidad:
- Identifica enfermedades que causan muertes tempranas.
- Ayuda a focalizar recursos en problemas que impactan la longevidad.
🧩 3. Años de Vida Ajustados por Discapacidad (AVAD o DALYs)
📘 Definición:
Los Años de Vida Ajustados por Discapacidad (AVAD) combinan la pérdida de años por muerte prematura (AVP) y los años vividos con discapacidad (AVD). Es una medida integral del impacto de las enfermedades en la calidad y cantidad de vida.
🧮 Fórmula:
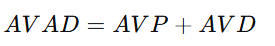
Donde:
- AVP: Años de vida perdidos (por muerte prematura).
- AVD: Años vividos con discapacidad, ponderados según su gravedad.
🌟 Ejemplo:
- Si un paciente con diabetes pierde 10 años de vida y vive 5 años con discapacidad moderada (ponderación 0.4), el cálculo es:
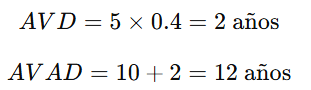
💡 Utilidad:
- Permite comparar el impacto de enfermedades fatales y no fatales.
- Usado en estudios globales (Ej. Carga Global de Enfermedad – GBD).
🌱 4. Esperanza de Vida Saludable (HALE)
📘 Definición:
La Esperanza de Vida Saludable (HALE) estima el número de años que una persona puede vivir con buena salud (sin discapacidad significativa).
🧮 Fórmula:
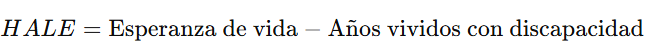
🌟 Ejemplo:
- Si la esperanza de vida es 75 años y se viven 10 años con discapacidad significativa (peso 0.5):
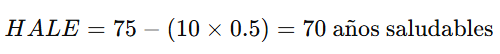
💡 Utilidad:
- Evalúa la calidad de vida y no solo la longevidad.
- Útil en políticas de promoción de salud y prevención.
📊 5. Evaluación del Peso de las Enfermedades en la Población
Las medidas de impacto permiten priorizar problemas de salud basándose en:
- Gravedad: Enfermedades con alta letalidad o discapacidad (Ej. cáncer avanzado).
- Frecuencia: Alta prevalencia (Ej. diabetes tipo 2).
- Años afectados: Enfoque en enfermedades crónicas o degenerativas.
- Edad afectada: Impacto es mayor si afecta a personas jóvenes.
🔍 Ejemplo comparativo:
- El AVP por cáncer de pulmón es alto debido a muertes tempranas.
- El AVAD de enfermedades crónicas como diabetes puede ser alto debido a años vividos con discapacidad.
- La HALE se ve reducida en países con alta prevalencia de enfermedades crónicas no transmisibles (ECNT).
💡 6. Ejemplos Comparativos Reales
📌 Caso 1: Carga de Enfermedad en COVID-19
- Altos AVP debido a muertes en adultos mayores.
- AVD significativo en casos de COVID persistente (long COVID).
- HALE disminuida en países afectados gravemente.
📌 Caso 2: Enfermedades Crónicas
- Diabetes tipo 2:
- AVD elevados por complicaciones (retinopatía, neuropatía).
- AVP relativamente bajos debido a larga evolución.
- Cáncer de mama:
- AVP variable según el estadio.
- AVD altos en supervivientes con secuelas de tratamiento.
🎓 Actividades sugeridas
💬 Discusión ABP:
Caso:
«En una región con alta mortalidad por enfermedades cardiovasculares y alta prevalencia de diabetes, ¿cuál de las medidas (AVP, AVAD, HALE) usarías para priorizar intervenciones? ¿Por qué?»
📊 Actividad práctica en R o Stata:
- Calcular los AVP y AVAD de una población con datos simulados.
- Comparar HALE entre dos regiones usando datos de morbilidad.
- Visualizar el impacto en un gráfico de barras.
🔹 BLOQUE 7: Medidas de Natalidad y Fertilidad
- Tasa bruta de natalidad.
- Tasa general y específica de fecundidad.
- Tasa de mortalidad infantil y neonatal.
- Indicadores perinatales y su utilidad.
🔹 BLOQUE 7: Medidas de Natalidad y Fertilidad
🌱 1. ¿Qué son las medidas de natalidad y fertilidad?
Las medidas de natalidad y fertilidad se utilizan para cuantificar el número de nacimientos en una población y evaluar la capacidad reproductiva de una comunidad. Son indicadores esenciales para el planeamiento demográfico y de salud pública.
📊 2. Tasa Bruta de Natalidad (TBN)
📘 Definición:
La Tasa Bruta de Natalidad (TBN) refleja el número de nacimientos vivos en una población durante un año por cada 1,000 habitantes.
🧮 Fórmula:

🌟 Ejemplo:
Si en una ciudad de 50,000 habitantes nacen 800 niños en un año: TBN=80050,000×1,000=16 nacimientos por cada 1,000 habitantesTBN = \frac{800}{50,000} \times 1,000 = 16 \text{ nacimientos por cada 1,000 habitantes}TBN=50,000800×1,000=16 nacimientos por cada 1,000 habitantes
💡 Utilidad:
- Mide el crecimiento poblacional.
- Se utiliza en estudios demográficos y análisis de tendencias.
👶 3. Tasa General de Fecundidad (TGF)
📘 Definición:
La Tasa General de Fecundidad (TGF) mide el número de nacimientos en mujeres en edad fértil (15 a 49 años) durante un año.
🧮 Fórmula:
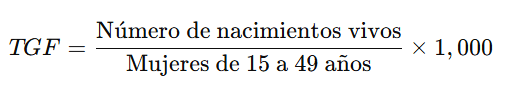
🌟 Ejemplo:
Si en una ciudad hay 10,000 mujeres en edad fértil y se registran 400 nacimientos: TGF=40010,000×1,000=40 nacimientos por cada 1,000 mujeres feˊrtilesTGF = \frac{400}{10,000} \times 1,000 = 40 \text{ nacimientos por cada 1,000 mujeres fértiles}TGF=10,000400×1,000=40 nacimientos por cada 1,000 mujeres feˊrtiles
💡 Utilidad:
- Mide la capacidad reproductiva de una comunidad.
- Es más precisa que la TBN porque considera solo mujeres en edad fértil.
📈 4. Tasa Específica de Fecundidad (TEF)
📘 Definición:
La Tasa Específica de Fecundidad (TEF) mide los nacimientos en mujeres de un grupo etario específico (ej. mujeres de 20-24 años).
🧮 Fórmula:

🌟 Ejemplo:

💡 Utilidad:
- Permite identificar grupos etarios de mayor fecundidad.
- Utilizado en políticas de salud reproductiva.
⚰️ 5. Tasa de Mortalidad Infantil (TMI)
📘 Definición:
La Tasa de Mortalidad Infantil (TMI) mide el número de muertes de niños menores de un año por cada 1,000 nacidos vivos en un año.
🧮 Fórmula:

🌟 Ejemplo:

💡 Utilidad:
- Indica la calidad de la atención perinatal y condiciones socioeconómicas.
- Es un indicador de desarrollo social y acceso a servicios de salud.
🍼 6. Tasa de Mortalidad Neonatal (TMN)
📘 Definición:
La Tasa de Mortalidad Neonatal (TMN) mide las muertes de recién nacidos en los primeros 28 días de vida.
🧮 Fórmula:

🌟 Ejemplo:
Si hubo 10 muertes neonatales entre 1,000 nacidos vivos:

💡 Utilidad:
- Refleja la calidad de atención obstétrica y neonatal.
- Útil para monitorear intervenciones en salud materna e infantil.
📊 7. Indicadores Perinatales y su Utilidad
📌 ¿Qué son los indicadores perinatales?
Son medidas que reflejan el estado de salud materna y del recién nacido durante el embarazo, el parto y el periodo neonatal.

🎓 Actividades sugeridas
💬 Discusión ABP:
Caso:
«En una comunidad rural, la TMI es 30 por 1,000 nacidos vivos y la TMN es 20 por 1,000. ¿Cuáles podrían ser las causas subyacentes y qué medidas preventivas implementarías?»
📊 Actividad práctica en R o Stata:
- Cargar datos de natalidad y mortalidad infantil.
- Calcular TBN, TGF, TEF, TMI y TMN.
- Comparar indicadores entre dos regiones usando gráficos de barras.
🔹 BLOQUE 8: Medidas de Asociación Epidemiológica
- Riesgo relativo (RR), odds ratio (OR), riesgo atribuible (RA).
- Asociación vs causalidad.
- Ejemplos aplicados: factores de riesgo y enfermedad.
- Interpretación para intervención y prevención.
🔹 BLOQUE 8: Medidas de Asociación Epidemiológica
📊 1. Introducción a las Medidas de Asociación
Las medidas de asociación epidemiológica son fundamentales para evaluar si existe una relación entre un factor de riesgo y una enfermedad. Permiten cuantificar el grado de asociación y estimar el riesgo o la probabilidad de que un evento ocurra en presencia de un factor específico.
💡 ¿Por qué son importantes?
- Determinan si una exposición aumenta el riesgo de enfermedad.
- Ayudan a identificar factores de riesgo modificables.
- Sirven para la planificación de intervenciones en salud pública.
🧮 2. Riesgo Relativo (RR)
📘 Definición:
El Riesgo Relativo (RR) compara la probabilidad de ocurrencia de un evento en el grupo expuesto frente al no expuesto.
🧮 Fórmula:

| Resultado | Interpretación |
|---|---|
| RR = 1 | No hay asociación entre la exposición y la enfermedad |
| RR > 1 | La exposición aumenta el riesgo (factor de riesgo) |
| RR < 1 | La exposición disminuye el riesgo (factor protector) |
🌟 Ejemplo:
En un estudio de tabaquismo y cáncer de pulmón:
- Incidencia en fumadores: 30/1,000
- Incidencia en no fumadores: 10/1,000
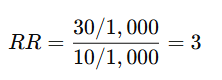
→ Los fumadores tienen 3 veces más riesgo de cáncer de pulmón que los no fumadores.
🔄 3. Odds Ratio (OR)
📘 Definición:
El Odds Ratio (OR) estima la probabilidad de ocurrencia de un evento frente a su no ocurrencia. Es especialmente útil en estudios de casos y controles.
🧮 Fórmula:
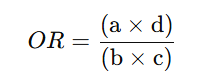
Donde:
- a: Casos expuestos
- b: Casos no expuestos
- c: Controles expuestos
- d: Controles no expuestos
| Resultado | Interpretación |
|---|---|
| OR = 1 | No hay asociación entre exposición y enfermedad |
| OR > 1 | Mayor probabilidad de la enfermedad con la exposición |
| OR < 1 | Menor probabilidad de la enfermedad con la exposición |
🌟 Ejemplo:
En un estudio de obesidad y diabetes tipo 2:
- Obesos con diabetes: 50
- Obesos sin diabetes: 100
- No obesos con diabetes: 20
- No obesos sin diabetes: 150
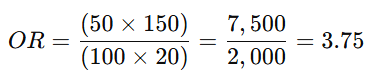
→ Los obesos tienen 3.75 veces más probabilidades de tener diabetes que los no obesos.
🔗 4. Riesgo Atribuible (RA)
📘 Definición:
El Riesgo Atribuible (RA) mide la diferencia de riesgo entre los expuestos y los no expuestos. Cuantifica el exceso de riesgo debido a la exposición.
🧮 Fórmula:

🌟 Ejemplo:
Si la incidencia de enfermedad cardiovascular en fumadores es de 20% y en no fumadores es de 5%:
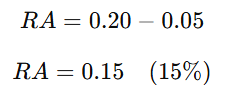
→ El 15% del riesgo de enfermedad cardiovascular en fumadores se atribuye al tabaquismo.
🪢 5. Asociación vs Causalidad
💡 Asociación:
- Relación estadística entre exposición y enfermedad.
- No necesariamente implica que uno cause el otro.
⚖️ Causalidad:
- Requiere pruebas adicionales y criterios (como los criterios de Bradford Hill).
- La asociación puede deberse a confusión, sesgo o azar.
Ejemplo:
El RR elevado entre el tabaquismo y el cáncer de pulmón indica una fuerte asociación; sin embargo, establecer causalidad requiere demostrar una relación directa y eliminar factores de confusión.
📝 6. Interpretación para Intervención y Prevención
- Si el RR o OR es alto, el factor debe ser priorizado en campañas preventivas.
- El RA permite estimar el impacto de eliminar la exposición en la población.
- La interpretación contextual es clave:
- ¿El aumento del riesgo es clínicamente significativo?
- ¿Existen factores de confusión que influyan en la asociación?
🧩 7. Ejemplos Aplicados: Factores de Riesgo y Enfermedad
📌 Caso 1: Tabaco y Cáncer de Pulmón
- RR: 20 (los fumadores tienen 20 veces más riesgo que los no fumadores).
- OR: 25 (en estudios retrospectivos).
- RA: 80% (gran impacto si se reduce el tabaquismo).
📌 Caso 2: Obesidad y Diabetes Tipo 2
- OR: 3.75 (los obesos tienen casi 4 veces más probabilidades de diabetes).
- Intervención: Programas de control de peso en poblaciones vulnerables.
🎓 Actividades sugeridas
💬 Discusión ABP:
Caso:
«En un estudio de hipertensión y enfermedad renal crónica, el OR es 4.5. ¿Es suficiente para concluir causalidad? ¿Qué otros factores considerarías?»
📊 Actividad práctica en R o Stata:
- Calcular el RR y el OR a partir de una tabla 2×2.
- Generar gráficos de barras para visualizar el riesgo relativo en grupos expuestos y no expuestos.
- Realizar un análisis de sensibilidad para identificar factores de confusión.
🔹 BLOQUE 9: Medidas de Impacto Clínico y de Intervención
- Número necesario a tratar (NNT) y dañar (NNH).
- Reducción absoluta y relativa del riesgo.
- Utilidad para decisiones clínicas y políticas públicas.
- Aplicación en guías de práctica clínica y evaluación de tratamientos.
🔹 BLOQUE 9: Medidas de Impacto Clínico y de Intervención
🩺 1. Introducción a las Medidas de Impacto Clínico
Las medidas de impacto clínico son fundamentales para evaluar la efectividad de intervenciones terapéuticas. Permiten cuantificar cuánto mejora o empeora la salud del paciente gracias a una intervención, ayudando en la toma de decisiones clínicas y de políticas de salud.
📊 2. Número Necesario a Tratar (NNT)
📘 Definición:
El Número Necesario a Tratar (NNT) representa el número de pacientes que deben recibir un tratamiento para prevenir un evento adverso (o lograr un resultado beneficioso) en uno de ellos.
🧮 Fórmula:
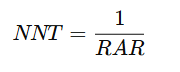
Donde:
- RAR (Reducción Absoluta del Riesgo) = Incidencia en el grupo control – Incidencia en el grupo tratado.
🌟 Ejemplo:
En un ensayo clínico, la incidencia de infarto en el grupo control es del 10% (0.10) y en el grupo tratado es del 5% (0.05).

Interpretación:
Es necesario tratar a 20 pacientes para prevenir un infarto en uno de ellos.
⚠️ 3. Número Necesario para Dañar (NNH)
📘 Definición:
El Número Necesario para Dañar (NNH) indica cuántos pacientes deben ser expuestos a un tratamiento para que uno de ellos experimente un evento adverso.
🧮 Fórmula:
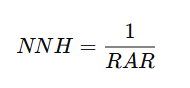
Donde:
- RAR se calcula como:
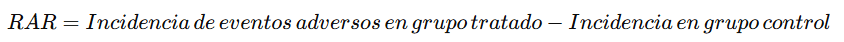
🌟 Ejemplo:
Si el tratamiento causa efectos adversos en el 4% (0.04) de los pacientes tratados y en el 2% (0.02) de los controles:
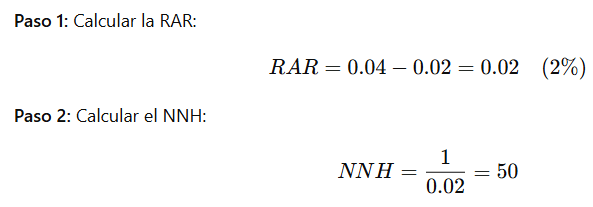
Interpretación:
Se espera que 1 de cada 50 pacientes tratados experimente un efecto adverso atribuible al tratamiento.
📉 4. Reducción Absoluta del Riesgo (RAR)
📘 Definición:
La RAR indica la diferencia de riesgo entre el grupo control y el grupo tratado.
🧮 Fórmula:

📈 5. Reducción Relativa del Riesgo (RRR)
📘 Definición:
La RRR cuantifica el porcentaje de reducción del riesgo con el tratamiento en comparación con el grupo control.
🧮 Fórmula:

🌟 Ejemplo:
Con los mismos datos anteriores:
- Incidencia en control: 10% (0.10)
- Incidencia en tratado: 5% (0.05)
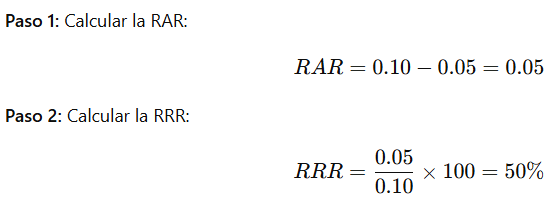
Interpretación:
El tratamiento reduce el riesgo de infarto en un 50% en comparación con no tratar.
🗺️ 6. Utilidad para Decisiones Clínicas y Políticas Públicas
- El NNT permite evaluar si el beneficio clínico justifica el uso del tratamiento.
- El NNH ayuda a ponderar los riesgos versus beneficios.
- Las RRR y RAR contextualizan el impacto clínico real de una intervención.
- Estas medidas son cruciales en guías de práctica clínica y en la evaluación de costo-efectividad.
📑 7. Aplicación en Guías de Práctica Clínica
Las guías clínicas generalmente presentan los resultados de estudios en términos de NNT y NNH para:
- Evaluar el valor terapéutico de un medicamento.
- Decidir sobre la implementación de políticas sanitarias.
- Facilitar el consentimiento informado con datos claros y precisos.
Ejemplo:
La guía de tratamiento para hipertensión puede indicar que el NNT para prevenir un infarto con un antihipertensivo específico es 25, pero el NNH para efectos secundarios graves es 200, lo que hace que el beneficio supere el riesgo.
🎓 Actividades sugeridas
💬 Discusión ABP:
Caso:
«Un nuevo fármaco reduce el riesgo de accidente cerebrovascular en un 40% en pacientes hipertensos. ¿Cuál es el NNT si la incidencia sin tratamiento es del 10%? ¿El beneficio justifica el costo del tratamiento?»
📊 Actividad práctica en R o Stata:
- Calcular NNT, NNH, RAR y RRR con datos de un ensayo clínico.
- Realizar un gráfico comparativo de NNT y NNH para varios tratamientos.
- Interpretar los resultados para guías clínicas.
STATA
🔹 BLOQUE 1: Fundamentos de la Vigilancia Epidemiológica
Aplicar conceptos de vigilancia epidemiológica mediante el cálculo de la tasa de incidencia y la tasa de prevalencia, utilizando los datos del dataset.
✅ Variables requeridas:
region: Clasificación geográfica (norte, sur, este, oeste).
casos: Número de casos registrados.
poblacion: Población total en la región.
📊 1. Cálculo de la Tasa de Incidencia:
📘 Fórmula:
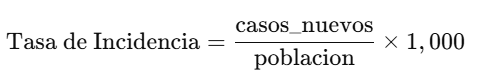
💻 Código en Stata:
* Calcular la tasa de incidencia por región
gen tasa_inc = (casos_nuevos / poblacion) * 1000
* Resumen de la tasa de incidencia
summarize tasa_inc
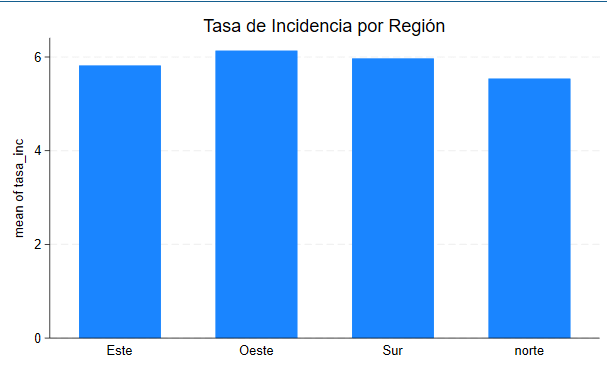
* Visualización gráfica
graph bar tasa_inc, over(region) title("Tasa de Incidencia por Región")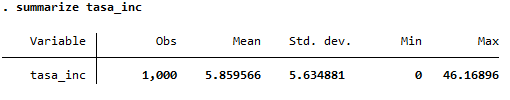
📊 2. Cálculo de la Tasa de Prevalencia:
📘 Fórmula:
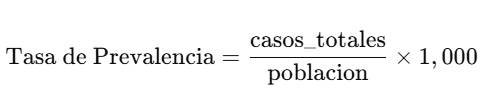
💻 Código en Stata:
* Calcular la tasa de prevalencia por región
gen tasa_prev = (casos_totales / poblacion) * 1000
* Resumen de la tasa de prevalencia
summarize tasa_prev
* Visualización gráfica
graph bar tasa_prev, over(region) title("Tasa de Prevalencia por Región")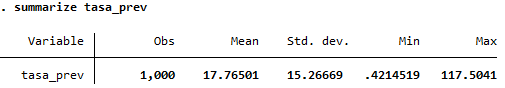
📊 2. Comparación de Tasas por Región:
💻 Código en Stata:
* Comparación de tasas de incidencia y prevalenciagraph bar (mean) tasa_inc (mean) tasa_prev, over(region)
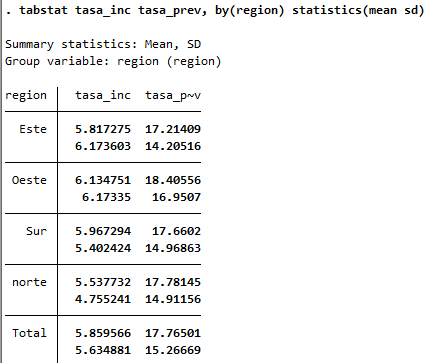
tabstat tasa_inc tasa_prev, by(region) statistics(mean sd)
* Gráfico comparativo
title("Comparación de Tasa de Incidencia y Prevalencia por Región")
legend(label(1 "Tasa de Incidencia") label(2 "Tasa de Prevalencia"))
blabel(bar)
💻 En Stata, el error «string variables not allowed in varlist» indica que estás intentando realizar cálculos o análisis con una variable de tipo cadena (string) en lugar de numérica.
Verificar el tipo de la variable:
describe regionConvertir la variable de string a numérica:
* Generar una variable numérica para la región
encode region, gen(region_num)
* Verificar la conversión
tabulate region_num
Usar la variable numérica en lugar de la variable string:
🔹 BLOQUE 2: Historia Natural de la Enfermedad
Convertir variables categóricas a numéricas:
* Recodificar tratamiento
gen tratamiento_num = .
replace tratamiento_num = 1 if tratamiento == "si"
replace tratamiento_num = 0 if tratamiento == "no"
* Recodificar evento_adverso
gen evento_num = .
replace evento_num = 1 if evento_adverso == "si"
replace evento_num = 0 if evento_adverso == "no"
* Recodificar sexo
gen sexo_num = .
replace sexo_num = 1 if sexo == "M"
replace sexo_num = 0 if sexo == "F"
📊 Análisis de Supervivencia:
Paso 1: Configurar el análisis de supervivencia:
* Definir el conjunto de datos para el análisis de supervivencia
stset tiempo_seguimiento, failure(evento_num == 1)¿Qué hace el comando stset?
El comando stset convierte el conjunto de datos en un formato adecuado para el análisis de supervivencia en Stata. Especifica tanto el tiempo de seguimiento como el evento de interés (por ejemplo, fallecimiento, recaída, etc.).
Explicación:
- tiempo_seguimiento: Es la variable que contiene el tiempo desde el inicio del estudio hasta el evento de interés o el final del seguimiento (censura).
- failure(evento_num == 1):
- La opción
failure()define el evento de interés. - En este caso,
evento_numes la variable que indica si ocurrió el evento (1) o no (0). - El comando especifica que un valor de 1 en la variable
evento_numindica que el evento ocurrió (es decir, hubo un «fallo» en términos de supervivencia).
- La opción
¿Qué significa esto en términos prácticos?
- A partir de este punto, Stata entiende que los datos están estructurados para análisis de supervivencia.
- Cada observación se vincula con un tiempo de seguimiento y una indicación de si ocurrió el evento o si se trata de un dato censurado (es decir, el evento no ocurrió durante el seguimiento).
Paso 2: Estimar curvas de supervivencia (Kaplan-Meier):
Curvas de supervivencia agrupadas por tratamiento y sexo
sts graph, by(tratamiento_num) title("Curvas de Supervivencia por Tratamiento")
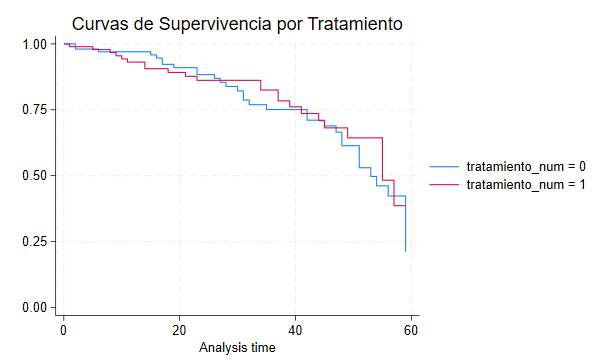
El tratamiento no parece tener un impacto claro y consistente en la supervivencia a lo largo del tiempo.
🔹 BLOQUE 3: Medidas de Morbilidad
📊 Análisis en Stata:
💻 1. Cargar el conjunto de datos:
* Cargar el archivo CSV de morbilidad
import delimited "dataset_morbilidad_ficticio.csv", clear
🌱 2. Verificar las variables necesarias:
* Verificar la estructura de los datos y las variables
describe id edad sexo region casos_nuevos casos_totales poblacion tiempo_seguimiento
📊 3. Calcular las Medidas de Morbilidad:
1. Incidencia Acumulada (IA):

* Calcular la incidencia acumulada
gen incidencia_acum = casos_nuevos / poblacion
summarize incidencia_acum
✅ Interpretación de la Media:
- El valor medio de 0.0038 (o 0.38%) indica que, en promedio, alrededor del 0.38% de la población en riesgo desarrolló la enfermedad durante el período de estudio.
- Esto sugiere una baja incidencia acumulada, lo que podría indicar que la enfermedad no se está propagando rápidamente en la población estudiada.
📈 Interpretación del Rango:
- Valor mínimo (0): Algunas regiones o grupos no presentaron casos nuevos durante el período estudiado, lo cual puede reflejar zonas donde la enfermedad no se ha manifestado.
- Valor máximo (0.0169 o 1.69%): La región con mayor incidencia acumulada presenta un 1.69% de la población afectada. Esto indica que en esa zona o subgrupo, la enfermedad tiene una mayor aparición en el período estudiado.
📊 Interpretación de la Desviación Estándar:
- Std. dev. (0.0030): La baja desviación estándar indica que la variación en la incidencia acumulada entre las regiones es pequeña. Esto sugiere que la enfermedad tiene una distribución relativamente homogénea en la mayoría de las regiones.
💡 Conclusión:
La distribución homogénea puede indicar que el riesgo está uniformemente distribuido entre la mayoría de las regiones, con pocas áreas críticas.
La baja incidencia acumulada promedio (0.38%) sugiere que la enfermedad tiene una baja propagación en general.
Sin embargo, existe variabilidad entre regiones, con algunos lugares alcanzando hasta el 1.69% de incidencia acumulada.
2. Tasa de Incidencia (TI):

* Calcular la tasa de incidencia
gen tasa_incidencia = casos_nuevos / (poblacion * tiempo_seguimiento)
summarize tasa_incidencia✅ Interpretación de la Media:
- El valor medio de 0.00031 indica que, en promedio, la tasa de incidencia es de aproximadamente 0.031% (o 3.1 casos por cada 10,000 personas-mes).
- Esto sugiere que la enfermedad tiene una baja tasa de incidencia, lo cual es común en enfermedades de baja transmisibilidad o de aparición esporádica.
📈 Interpretación del Rango:
- Valor mínimo (0): Algunas regiones o grupos no presentaron ningún caso nuevo durante el tiempo de seguimiento.
- Valor máximo (0.00952 o 0.952%): La región con la mayor tasa de incidencia tiene 0.952 casos por cada 100 personas-mes. Esto podría indicar una zona con un brote o mayor propagación de la enfermedad.
📊 Interpretación de la Desviación Estándar:
- Std. dev. (0.00097): La baja desviación estándar refleja que la tasa de incidencia es bastante homogénea entre las regiones, aunque hay algunas zonas con tasas más altas.
- La poca variación indica que la mayoría de las regiones presentan tasas de incidencia similares.
💡 Conclusión:
- La baja tasa de incidencia promedio (0.031%) indica que la enfermedad se propaga lentamente en la población.
- Aunque algunas regiones presentan tasas más altas (hasta 0.952%), la mayoría están en el rango bajo, lo que sugiere un comportamiento no epidémico.
- La baja desviación estándar sugiere que la incidencia se mantiene relativamente constante en la mayoría de los grupos.
3. Prevalencia Puntual (PP):
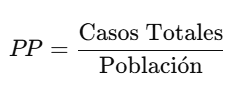
* Calcular la prevalencia puntual
gen prevalencia_puntual = casos_totales / poblacion
summarize prevalencia_puntual✅ Interpretación de la Media:
- El valor medio de 0.0238 indica que, en promedio, la prevalencia puntual es del 2.38%.
- Esto significa que, en cualquier momento dado, alrededor del 2.38% de la población está afectada por la enfermedad.
- Una prevalencia puntual baja sugiere que la enfermedad no es muy común en la población en el momento del análisis.
📈 Interpretación del Rango:
- Valor mínimo (0.0042 o 0.42%): En algunas regiones, menos del 0.5% de la población está afectada en un momento dado, lo que sugiere un bajo impacto en esas zonas.
- Valor máximo (0.0818 o 8.18%): En la región con mayor prevalencia puntual, aproximadamente el 8.18% de la población está afectada. Esto indica una zona con mayor carga de la enfermedad.
📊 Interpretación de la Desviación Estándar:
- Std. dev. (0.0150): La desviación estándar relativamente baja sugiere que la variación en la prevalencia entre regiones no es muy grande.
- La mayoría de las regiones están agrupadas en torno a la media del 2.38%, lo que indica homogeneidad en la prevalencia puntual.
💡 Conclusión:
- La prevalencia puntual promedio del 2.38% indica que la enfermedad no es altamente prevalente en la población.
- Aunque algunas regiones presentan una prevalencia de hasta el 8.18%, la mayoría de los valores se mantienen relativamente bajos.
- La distribución homogénea de la prevalencia puntual sugiere que no hay focos significativos de concentración de la enfermedad en el momento del análisis.
4. Prevalencia de Período (PP):

* Calcular la prevalencia de período
gen prevalencia_periodo = (casos_totales + casos_nuevos) / poblacion
summarize prevalencia_periodo✅ Interpretación de la Media:
- El valor medio de 0.0276 indica que, en promedio, la prevalencia de período es del 2.76%.
- Esto significa que, durante el período de observación, aproximadamente el 2.76% de la población estuvo afectada por la enfermedad en algún momento.
- Una prevalencia de período relativamente baja sugiere que la enfermedad no es común durante el tiempo estudiado.
📈 Interpretación del Rango:
- Valor mínimo (0.0061 o 0.61%): Algunas regiones tienen una baja carga de enfermedad en todo el período, lo que indica un bajo impacto acumulativo.
- Valor máximo (0.0872 o 8.72%): La región con mayor prevalencia de período muestra que casi el 8.72% de la población estuvo afectada en algún momento del período de estudio.
- La diferencia entre el mínimo y el máximo sugiere que existen variaciones regionales significativas en la carga de la enfermedad.
📊 Interpretación de la Desviación Estándar:
- Std. dev. (0.0167): La desviación estándar no es muy alta, lo que indica que la variabilidad entre regiones es moderada.
- La mayoría de las regiones presentan valores cercanos a la media, pero hay algunas zonas con valores extremos.
📈 4. Visualización de Medidas de Morbilidad:
Gráfico de Barras Comparativo por Región y sin región
* Gráfico comparativo de medidas de morbilidad por región
graph bar (mean) incidencia_acum (mean) tasa_incidencia (mean) prevalencia_puntual (mean) prevalencia_periodo, over(region) title("Comparación de Medidas de Morbilidad por Región")graph bar (mean) incidencia_acum (mean) tasa_incidencia (mean) prevalencia_puntual (mean) prevalencia_periodo, title("Comparación de Medidas de Morbilidad")
✅ Interpretación de Resultados:
- Incidencia Acumulada (IA):
- Mide el riesgo de desarrollar la enfermedad en un período determinado.
- Una IA alta indica una mayor proporción de nuevos casos.
- Tasa de Incidencia (TI):
- Refleja la rapidez con la que aparecen los nuevos casos en la población.
- Alta TI puede sugerir un brote o aumento rápido de la enfermedad.
- Prevalencia Puntual (PP):
- Proporción de individuos que presentan la enfermedad en un momento específico.
- Alta PP sugiere que la enfermedad es común en la población.
- Prevalencia de Período (PP):
- Incluye todos los casos a lo largo del tiempo de seguimiento.
- Alta PP de período es indicativa de enfermedades crónicas o de larga duración.
🔹 BLOQUE 4: Medidas de Mortalidad
💻 1. Cargar el conjunto de datos:
stataCopiarEditar* Cargar el archivo CSV de mortalidad
import delimited "dataset_mortalidad_ficticio.csv", clear
🌱 2. Verificar las variables necesarias:
* Verificar la estructura de los datos y las variables
describe id edad sexo region muertes poblacion casos
📊 3. Calcular las Medidas de Mortalidad:
1. Tasa de Mortalidad General (TMG):

* Calcular la tasa de mortalidad general
gen tasa_mortalidad_general = (muertes / poblacion) * 1000
summarize tasa_mortalidad_general
2. Tasa de Mortalidad Específica por Edad (TME):
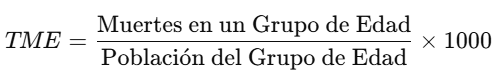
* Calcular la tasa de mortalidad específica por edad (ejemplo: mayores de 60 años)
gen tasa_mortalidad_edad = (muertes / poblacion) * 1000 if edad >= 60
summarize tasa_mortalidad_edad✅ Interpretación de la Media:
- El valor medio de 3.92 indica que, en promedio, hay 3.92 muertes por cada 1,000 personas en la población estudiada.
- Esta es una tasa relativamente baja, lo que sugiere que, en general, la mortalidad en la población es moderada.
📈 Interpretación del Rango:
- Valor mínimo (0): Algunas regiones o grupos no presentan muertes durante el período de observación, lo cual puede reflejar zonas de bajo riesgo o buena cobertura sanitaria.
- Valor máximo (18.27): La región con mayor mortalidad general tiene aproximadamente 18.27 muertes por cada 1,000 personas.
- Esta variación puede indicar diferencias significativas en acceso a salud, carga de enfermedad o características demográficas.
📊 Interpretación de la Desviación Estándar:
- Std. dev. (3.38): La desviación estándar relativamente alta sugiere que hay una variabilidad considerable entre las regiones en cuanto a la tasa de mortalidad.
- Esto significa que algunas regiones están mucho más afectadas que otras.
3. Tasa de Letalidad (TL):

* Calcular la tasa de letalidad
gen tasa_letalidad = (muertes / casos) * 100
summarize tasa_letalidad✅ Interpretación de la Media:
- El valor medio de 19.76 indica que, en promedio, la tasa de letalidad es del 19.76%.
- Esto significa que aproximadamente 1 de cada 5 personas con la enfermedad fallecen, lo que indica una alta gravedad de la enfermedad en la población estudiada.
📈 Interpretación del Rango:
- Valor mínimo (0): Algunas regiones o grupos no presentan muertes por la enfermedad, lo que puede reflejar casos leves o tratamientos efectivos en esas áreas.
- Valor máximo (90.48%): En la región con la mayor letalidad, 9 de cada 10 personas que contraen la enfermedad fallecen.
- Esto puede indicar una zona con mayor virulencia de la enfermedad, menor acceso a tratamiento o características particulares en la población.
📊 Interpretación de la Desviación Estándar:
- Std. dev. (16.61): La alta desviación estándar refleja que la letalidad varía significativamente entre las regiones.
- Esto sugiere que la gravedad de la enfermedad no es uniforme, y puede depender de factores específicos de cada región o población.
4. Mortalidad Proporcional (MP):
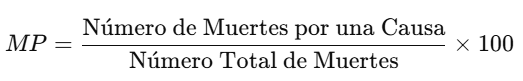
* Calcular la mortalidad proporcional
egen total_muertes = total(muertes)
gen mortalidad_proporcional = (muertes / total_muertes) * 100
summarize mortalidad_proporcional
✅ Interpretación de la Media:
- El valor medio de 0.5 indica que, en promedio, el 50% de las muertes en el conjunto de datos son atribuibles a la causa específica que estamos evaluando.
- Esto significa que, en la mitad de los casos, la causa de muerte evaluada representa la mitad del total de muertes.
- La mortalidad proporcional del 50% sugiere que la causa estudiada tiene un impacto significativo en la carga total de muertes.
📈 Interpretación del Rango:
- Valor mínimo (0): En algunas observaciones, la mortalidad proporcional es 0, lo que sugiere que no hubo muertes atribuidas a esa causa específica en ciertos grupos o regiones.
- Valor máximo (1.01 o 100.7%): Esto indica que en algunos casos, todas las muertes registradas (100%) fueron atribuidas a la causa en estudio.
- El valor máximo ligeramente superior a 1 puede deberse a redondeos en los cálculos o diferencias menores en la suma de las proporciones.
📊 Interpretación de la Desviación Estándar:
- Std. dev. (0.31): La desviación estándar moderadamente alta indica que la proporción de muertes varía considerablemente entre las observaciones.
- Esto sugiere que en algunas regiones o grupos, la causa de muerte evaluada tiene un impacto mucho mayor que en otras.
📈 4. Visualización de Medidas de Mortalidad:
Gráfico de Barras Comparativo:
* Gráfico comparativo de medidas de mortalidadgraph bar (mean) tasa_mortalidad_general (mean) tasa_letalidad (mean) mortalidad_proporcional, title("Medidas de Mortalidad")
✅ Interpretación de Resultados:
- Tasa de Mortalidad General (TMG):
- Indica la probabilidad de morir en la población general.
- Una TMG alta puede sugerir problemas de salud pública importantes.
- Tasa de Mortalidad Específica (TME):
- Refleja el riesgo de morir en un grupo de edad específico.
- Es útil para identificar grupos vulnerables, como personas mayores.
- Tasa de Letalidad (TL):
- Indica la gravedad de la enfermedad, mostrando el porcentaje de casos que resultan en muerte.
- Una TL alta sugiere que la enfermedad es particularmente peligrosa o mal manejada.
- Mortalidad Proporcional (MP):
- Muestra la proporción de muertes atribuibles a una causa específica dentro del total de muertes.
- Permite evaluar el impacto relativo de diferentes causas de muerte.
🔹 BLOQUE 5: Medidas de Mortalidad
📊 Análisis en Stata:
💻 1. Cargar el conjunto de datos:
* Cargar el archivo CSV de comparación de mortalidad
import delimited "dataset_comparacion_mortalidad.csv", clear
🌱 2. Verificar las variables necesarias:
* Verificar la estructura de los datos y las variables
describe id edad sexo region grupo muertes poblacion casos
📊 3. Calcular las Medidas de Mortalidad Comparativa:
1. Tasa de Mortalidad Cruda (TMC):

* Calcular la tasa de mortalidad cruda
gen tasa_mortalidad_cruda = (muertes / poblacion) * 1000
summarize tasa_mortalidad_cruda✅ Interpretación de la Media:
- El valor medio de 3.84 indica que, en promedio, hay aproximadamente 3.84 muertes por cada 1,000 personas en la población estudiada.
- Esta tasa sugiere que la mortalidad en general es baja, lo que podría reflejar un contexto con buena cobertura sanitaria o bajo impacto de la enfermedad.
📈 Interpretación del Rango:
- Valor mínimo (0): Algunas regiones o grupos no presentan muertes, lo que podría indicar zonas con bajo riesgo o buena gestión sanitaria.
- Valor máximo (17.91): La región con mayor mortalidad tiene aproximadamente 17.91 muertes por cada 1,000 personas.
- Esta variación refleja que existen disparidades significativas en la mortalidad entre las diferentes regiones o grupos.
📊 Interpretación de la Desviación Estándar:
- Std. dev. (3.43): La desviación estándar relativamente alta indica que la tasa de mortalidad cruda varía considerablemente entre las observaciones.
- Esto sugiere que algunas regiones tienen tasas mucho más altas que otras, lo que podría estar relacionado con factores demográficos, socioeconómicos o de salud pública.
2. Tasa de Mortalidad Ajustada (TMA) – Método Directo:
- Utilizaremos una población estándar ficticia para el ajuste.
Crear Población Estándar:
* Definir la población estándar ficticia (por edad)
gen poblacion_estandar = 10000 if edad >= 60
replace poblacion_estandar = 20000 if edad < 60
Calcular la Tasa Ajustada:
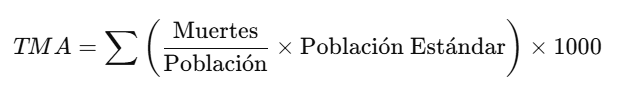
* Calcular la tasa de mortalidad ajustada
gen tasa_mortalidad_ajustada = (muertes / poblacion) * poblacion_estandar * 1000
summarize tasa_mortalidad_ajustada💡 ¿Qué significan los valores 10,000 y 20,000 en la Población Estándar?
En el contexto del análisis de mortalidad ajustada, los valores 10,000 y 20,000 son números arbitrarios que se utilizaron para simular una población estándar en el cálculo de la tasa de mortalidad ajustada.
📊 ¿Por qué utilizamos estos números?
- Representación de Grupos Etarios:
- En muchos estudios demográficos y epidemiológicos, las poblaciones mayores de 60 años suelen ser menos numerosas en comparación con los grupos de edad más jóvenes.
- Por esta razón, asignamos un valor menor (10,000) a la población estándar de personas de 60 años o más.
- Los menores de 60 años, siendo más numerosos, reciben un valor mayor (20,000).
3. Comparación de Mortalidad entre Grupos:
* Comparar tasas de mortalidad cruda y ajustada entre grupos
bysort grupo: summarize tasa_mortalidad_cruda tasa_mortalidad_ajustada✅ Interpretación de la Tasa de Mortalidad Cruda:
- Grupo A:
- Media: 3.94 muertes por cada 1,000 personas.
- Desviación estándar: 3.63, lo que indica variabilidad moderada en la mortalidad entre observaciones.
- Rango: La mortalidad varía desde 0 a 17.91.
- Grupo B:
- Media: 3.73 muertes por cada 1,000 personas.
- Desviación estándar: 3.22, ligeramente menor que el Grupo A.
- Rango: Varía entre 0 y 16.48.
Comparación: La tasa de mortalidad cruda es similar entre ambos grupos, con una leve diferencia a favor del Grupo A (mayor).
✅ Interpretación de la Tasa de Mortalidad Ajustada:
- Grupo A:
- Media: 63,713.24 muertes ajustadas por cada 1,000 personas.
- Desviación estándar: 69,488.26, indicando alta variabilidad.
- Rango: Varía desde 0 a 358,209.
- Grupo B:
- Media: 56,956.23 muertes ajustadas por cada 1,000 personas.
- Desviación estándar: 55,445.23, menor que el Grupo A, pero aún significativa.
- Rango: Varía entre 0 y 329,670.
Comparación:
- Aunque la tasa cruda es similar en ambos grupos, la tasa ajustada es considerablemente mayor en el Grupo A.
- Esto puede indicar que el Grupo A tiene una población más envejecida o vulnerable, lo que se refleja al ajustar la tasa considerando la estructura etaria.
- La alta desviación estándar en ambos grupos sugiere que la mortalidad no es uniforme, presentando diferencias significativas según la edad o el contexto.
4. Comparación de Mortalidad entre Regiones:
* Comparar tasas de mortalidad cruda y ajustada entre regiones
bysort region: summarize tasa_mortalidad_cruda tasa_mortalidad_ajustada✅ Interpretación de la Tasa de Mortalidad Cruda (TMC):
- Mayor Tasa Cruda:
- La región Norte (4.10) presenta la tasa de mortalidad cruda más alta.
- Menor Tasa Cruda:
- La región Oeste (3.62) tiene la menor tasa cruda.
- Variabilidad:
- La desviación estándar es similar en todas las regiones, alrededor de 3.2 a 3.8, lo que sugiere una distribución de mortalidad similar entre regiones.
✅ Interpretación de la Tasa de Mortalidad Ajustada (TMA):
- Mayor Tasa Ajustada:
- La región Norte (68822.86) también presenta la tasa ajustada más alta, lo que indica que incluso tras el ajuste por edad, sigue siendo la región con mayor mortalidad.
- Menor Tasa Ajustada:
- La región Oeste (56191.26) mantiene una tasa ajustada más baja, lo que indica que tiene menos mortalidad relativa, incluso después del ajuste.
- Variabilidad:
- La alta desviación estándar (especialmente en el Sur, 73283) indica que la mortalidad ajustada varía considerablemente dentro de la región.
📈 Interpretación Comparativa:
- Concordancia Cruda vs Ajustada:
- Las regiones con altas tasas crudas también muestran altas tasas ajustadas (como el Norte).
- Esto sugiere que la alta mortalidad en el Norte no es solo un efecto de la estructura etaria, sino que puede haber otros factores contextuales involucrados.
- Desviación Estandar Alta:
- La región Sur tiene la mayor variabilidad en la tasa ajustada, lo que sugiere diferencias internas significativas (posiblemente por subgrupos de alto riesgo).
- Disparidades Regionales:
- Aunque la región Oeste tiene la menor tasa cruda, sigue mostrando valores máximos altos (358,209) en la tasa ajustada, lo que podría indicar puntos específicos con alta mortalidad.
✅ Interpretación de Resultados:
- Tasa de Mortalidad Cruda (TMC):
- Muestra la mortalidad observada directamente en la población.
- No ajusta por diferencias en estructura etaria u otros factores.
- Tasa de Mortalidad Ajustada (TMA):
- Ajusta por diferencias demográficas (edad).
- Permite hacer comparaciones más equitativas entre poblaciones con estructuras diferentes.
- Comparación entre Grupos:
- Identificar si el grupo A o el grupo B presenta mayores tasas de mortalidad.
- Evaluar si las tasas crudas y ajustadas presentan discrepancias significativas.
- Comparación entre Regiones:
- Determinar si alguna región presenta mortalidad más alta.
- Identificar si el ajuste cambia el orden de regiones con mayor mortalidad.
🔹 BLOQUE 6: Medidas de Impacto en Salud Pública
💻 Análisis en Stata:
1. Cargar el conjunto de datos:
* Cargar el archivo CSV de medidas de impacto en salud pública
import delimited "dataset_impacto_salud.csv", clear
2. Verificar las variables necesarias:
* Verificar la estructura de los datos y las variables
describe id edad muertes esperanza_vida años_discapacidad factor_discapacidad
* Renombrar la variable con caracteres incorrectos
rename aÃos_discapacidad años_discapacidad
3. Calcular las Medidas de Impacto:
1. Años de Vida Perdidos (AVP):
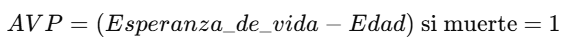
* Calcular los Años de Vida Perdidos (AVP)
gen avp = (esperanza_vida - edad) if muertes == 1
summarize avp
✅ Interpretación de la Media:
- El valor medio de 12.83 indica que, en promedio, los pacientes que fallecieron perdieron 12.83 años de vida en comparación con la esperanza de vida esperada.
- Esto refleja un impacto significativo de mortalidad prematura en la población estudiada.
📈 Interpretación del Rango:
- Valor mínimo (-27):
- Un valor negativo en los AVP indica que algunas personas fallecieron a una edad mayor a la esperanza de vida.
- Esto puede suceder si un individuo vive más años de lo esperado en su contexto o grupo etario.
- Valor máximo (50):
- Algunas personas fallecieron hasta 50 años antes de lo esperado.
- Esto refleja muertes prematuras significativas.
📊 Interpretación de la Desviación Estándar:
- Std. dev. (18.91):
- La alta desviación estándar sugiere una gran variabilidad en los AVP, indicando que algunos individuos pierden muchos años de vida mientras que otros tienen valores cercanos a cero (o negativos).
- Esto puede estar relacionado con la heterogeneidad en las causas de muerte o la variación en la esperanza de vida según el grupo etario.
2. Años de Vida con Discapacidad (AVND):
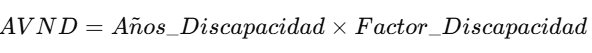
* Calcular los Años de Vida con Discapacidad (AVND)
gen avnd = años_discapacidad * factor_discapacidad
summarize avnd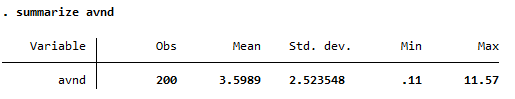
✅ Interpretación de la Media:
- El valor medio de 3.60 indica que, en promedio, las personas afectadas viven aproximadamente 3.6 años con discapacidad durante el tiempo de seguimiento.
- Esto refleja una carga de morbilidad significativa en la población estudiada.
📈 Interpretación del Rango:
- Valor mínimo (0.11):
- Algunos individuos viven con poca discapacidad o durante un corto periodo de tiempo.
- Valor máximo (11.57):
- En algunos casos, la discapacidad es más prolongada o tiene un impacto mayor (factor de discapacidad alto).
- Esto refleja la variabilidad en la duración y el impacto de la discapacidad dentro de la población.
📊 Interpretación de la Desviación Estándar:
- Std. dev. (2.52):
- La desviación estándar indica una variabilidad moderada en los años de vida con discapacidad.
- Esto sugiere que, aunque la media sea 3.60, hay individuos que experimentan tanto periodos cortos como largos de discapacidad.
3. Años de Vida Ajustados por Discapacidad (AVAD):
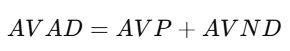
* Calcular los Años de Vida Ajustados por Discapacidad (AVAD)
gen avad = avp + avnd
summarize avad
✅ Interpretación de la Media:
- La media de 16.37 indica que, en promedio, cada persona afectada experimenta 16.37 años de vida perdidos o vividos con discapacidad.
- Esto refleja una carga combinada significativa de mortalidad prematura y discapacidad en la población.
📈 Interpretación del Rango:
- Valor mínimo (-23.84):
- Un valor negativo indica que algunos individuos vivieron más tiempo de lo esperado (AVP negativo) o que la discapacidad tuvo un impacto leve.
- Esto puede deberse a casos en los que la persona sobrevivió más allá de la esperanza de vida esperada.
- Valor máximo (54.10):
- Indica casos donde la combinación de muerte prematura y discapacidad severa generó una alta carga de años perdidos o vividos con discapacidad.
📊 Interpretación de la Desviación Estándar:
- Std. dev. (18.97):
- La alta desviación estándar refleja una gran variabilidad en los AVAD.
- Esto sugiere que algunas personas tienen pérdidas leves o incluso negativas, mientras que otras presentan cargas muy altas.
- La heterogeneidad puede deberse a diferencias en el impacto de enfermedades específicas o a variación en los grupos etarios.
4. Esperanza de Vida Saludable (EVS):

* Calcular la Esperanza de Vida Saludable (EVS)
gen evs = esperanza_vida - avad
summarize evs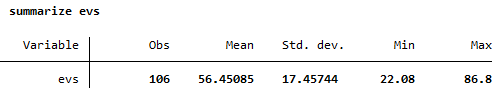
✅ Interpretación de la Media:
- La media de 56.45 indica que, en promedio, cada persona en la población puede esperar vivir 56.45 años sin discapacidad o enfermedad significativa.
- Este valor refleja la calidad de vida esperada en términos de salud en la población estudiada.
📈 Interpretación del Rango:
- Valor mínimo (22.08):
- Algunos individuos presentan una esperanza de vida saludable muy baja, lo que sugiere una alta carga de enfermedad o discapacidad.
- Valor máximo (86.80):
- Algunos individuos tienen una alta esperanza de vida saludable, lo que indica que viven casi toda su vida sin enfermedad significativa.
- El rango amplio sugiere que existen diferencias significativas en la calidad de vida entre subgrupos.
📊 Interpretación de la Desviación Estándar:
- Std. dev. (17.46):
- La desviación estándar relativamente alta indica una gran variabilidad en la expectativa de vida saludable entre los individuos.
- Esto sugiere que existen factores que afectan desigualmente la salud de la población, como enfermedades crónicas o diferencias socioeconómicas.
✅ Interpretación de Resultados:
- Años de Vida Perdidos (AVP):
- Cuantifican los años que no se vivieron debido a una muerte prematura.
- Valores altos indican una carga importante de mortalidad temprana.
- Años de Vida con Discapacidad (AVND):
- Miden el tiempo vivido con discapacidad o enfermedad crónica.
- Valores elevados reflejan enfermedades prolongadas o severas.
- Años de Vida Ajustados por Discapacidad (AVAD):
- Combinan el impacto de mortalidad prematura y discapacidad.
- Valores altos indican una carga global significativa de la enfermedad.
- Esperanza de Vida Saludable (EVS):
- Representa los años esperados sin enfermedad o discapacidad.
- Valores bajos sugieren que la salud de la población está comprometida.
🔹 BLOQUE 7: Medidas de Natalidad y Fertilidad
Comando para Crear Dataset:
* Crear el dataset ficticio en Stata
clear
set obs 200
* Variables generales
gen nacimientos = round(runiform() * 100)
gen poblacion = round(runiform() * 10000 + 5000)
gen mujeres_edad_fertil = round(poblacion * 0.2)
gen muertes_infantiles = round(runiform() * 20)
gen muertes_neonatales = round(muertes_infantiles * 0.6)
* Guardar el dataset
save dataset_natalidad.dta, replace📊 1. Cargar el conjunto de datos:
stataCopiarEditar* Cargar el dataset de natalidad y fertilidad
use dataset_natalidad.dta, clear
✅ 2. Calcular las Medidas de Natalidad y Fertilidad:
1. Tasa Bruta de Natalidad (TBN):
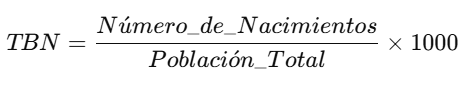
* Calcular la Tasa Bruta de Natalidad
gen tbn = (nacimientos / poblacion) * 1000
summarize tbn
- Interpretación: La TBN refleja el número de nacimientos por cada 1,000 habitantes en la población total.
2. Tasa General de Fecundidad (TGF):
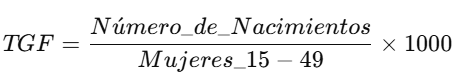
* Calcular la Tasa General de Fecundidad
gen tgf = (nacimientos / mujeres_edad_fertil) * 1000
summarize tgf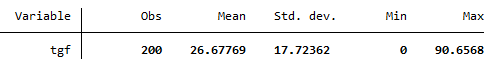
- Interpretación: La TGF mide los nacimientos en relación a las mujeres en edad fértil, lo que indica el nivel de fecundidad en esta población específica.
3. Tasa de Mortalidad Infantil (TMI):

* Calcular la Tasa de Mortalidad Infantil
gen tmi = (muertes_infantiles / nacimientos) * 1000
summarize tmi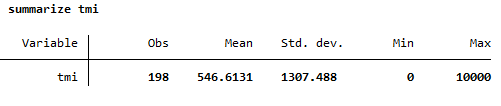
- Interpretación: La TMI muestra el número de muertes de menores de 1 año por cada 1,000 nacidos vivos, indicando la vulnerabilidad de los lactantes.
4. Tasa de Mortalidad Neonatal (TMN):
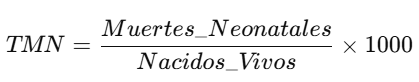
* Calcular la Tasa de Mortalidad Neonatal
gen tmn = (muertes_neonatales / nacimientos) * 1000
summarize tmn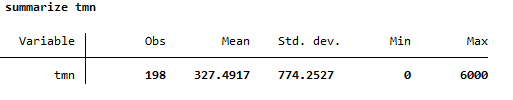
- Interpretación: La TMN refleja la mortalidad en los primeros 28 días de vida, lo que indica problemas en el cuidado perinatal.
🔹 BLOQUE 8: Medidas de Asociación Epidemiológica
💻 Creación del Dataset Ficticio en Stata:
Comando para Crear Dataset:
*Crear el dataset ficticio en Stata
clear
set obs 200
* Generar variables categóricas para exposición y evento
gen exposicion = round(runiform())
gen evento = round(runiform())
* Guardar el dataset
save dataset_asociacion.dta, replace
💻 Análisis en Stata:
1. Cargar el conjunto de datos:
* Cargar el dataset de medidas de asociación
use dataset_asociacion.dta, clear
2. Tabulación Cruzada:
* Tabla de contingencia para exposición y evento
tabulate exposicion evento
3. Calcular el Riesgo Relativo (RR):
* Calcular el Riesgo Relativo
cs evento exposicion
- Interpretación: El RR cuantifica cuánto mayor es el riesgo de enfermedad en el grupo expuesto en comparación con el no expuesto.
- RR > 1: El riesgo es mayor en los expuestos.
- RR < 1: El riesgo es menor en los expuestos.
- RR = 1: No hay asociación.
✅ Medidas de Riesgo:
a) Riesgo en Expuestos:
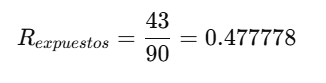
- Significa que el 47.8% de los individuos expuestos presentaron el evento.
b) Riesgo en No Expuestos:
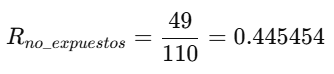
- Significa que el 44.5% de los individuos no expuestos presentaron el evento.
📈 Medidas de Asociación:
1. Riesgo Relativo (RR):
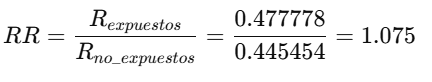
- Interpretación:
- El riesgo en el grupo expuesto es 1.08 veces (o 8% mayor) en comparación con el grupo no expuesto.
- Como el RR ≈ 1, indica que no hay una fuerte asociación entre la exposición y el evento.
- El Intervalo de Confianza (IC) 95% (0.79 – 1.45) incluye el valor 1, lo que sugiere que la asociación no es estadísticamente significativa.
2. Diferencia de Riesgo (Risk Difference):
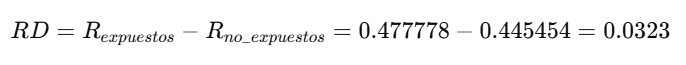
- Interpretación:
- El exceso de riesgo atribuible a la exposición es del 3.23%.
- El IC 95% (-0.1065 a 0.1712) incluye el cero, indicando que la diferencia no es significativa.
3. Fracción Atribuible en Expuestos (FAE):
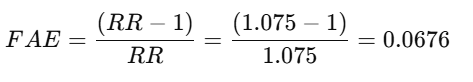
- Interpretación:
- El 6.76% del riesgo en los expuestos puede atribuirse a la exposición.
4. Fracción Atribuible Poblacional (FAP):
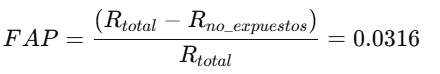
- Interpretación:
- El 3.16% del riesgo en la población total se puede atribuir a la exposición.
📊 Prueba de Chi-Cuadrado:
- chi2(1) = 0.21, Pr > chi2 = 0.6482
- Interpretación:
- Un valor de p > 0.05 indica que no hay evidencia estadísticamente significativa para rechazar la hipótesis nula.
- Esto sugiere que no existe una diferencia significativa entre los grupos expuestos y no expuestos en cuanto a la ocurrencia del evento.
💡 Conclusiones:
- El RR ≈ 1.08 indica que el riesgo es similar en ambos grupos (expuestos y no expuestos).
- El OR no se presenta porque el comando
csestá diseñado para calcular el Riesgo Relativo (RR), no el OR. - La prueba de chi-cuadrado no es significativa (p = 0.6482), lo que respalda la falta de asociación entre exposición y evento.
- La fracción atribuible en expuestos (6.76%) es pequeña, indicando un impacto limitado de la exposición.
4. Calcular el Odds Ratio (OR):
* Calcular el Odds Ratio
cc evento exposicion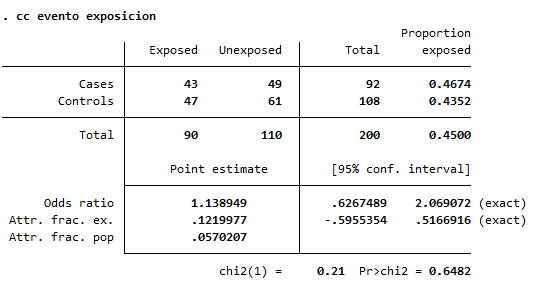
✅ Medidas de Asociación:
1. Odds Ratio (OR):
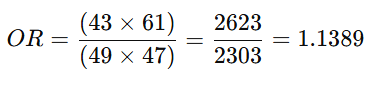
- Interpretación:
- El OR = 1.14 indica que los individuos expuestos tienen 1.14 veces (o un 14% más) de probabilidades de presentar el evento en comparación con los no expuestos.
- El Intervalo de Confianza (IC) 95% (0.63 – 2.07) incluye el valor 1, lo que significa que la asociación no es estadísticamente significativa.
- p > 0.05 (p = 0.6482) refuerza que no hay diferencia significativa entre los grupos.
2. Fracción Atribuible en Expuestos (FAE):
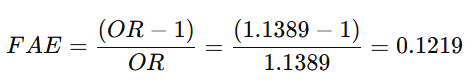
- Interpretación:
- El 12.2% del riesgo en los expuestos puede atribuirse directamente a la exposición.
- Como el IC incluye valores negativos (-0.59 a 0.52), esta fracción no es estadísticamente significativa.
3. Fracción Atribuible Poblacional (FAP):
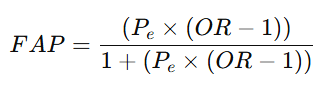
Donde:
- PeP_ePe = Proporción de expuestos en la población = 0.45
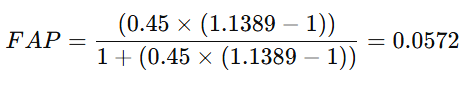
- Interpretación:
- El 5.7% del riesgo en la población puede atribuirse a la exposición.
- Este valor es bajo y el intervalo de confianza incluye valores negativos (-0.59 a 0.52), lo que indica falta de significancia estadística.
📈 Prueba de Chi-Cuadrado:
- chi2(1) = 0.21, Pr > chi2 = 0.6482
- Interpretación:
- El valor de p = 0.6482 indica que no hay evidencia suficiente para rechazar la hipótesis nula.
- Esto significa que no existe una diferencia significativa entre los grupos expuestos y no expuestos en cuanto a la ocurrencia del evento.
- Interpretación: El OR compara las probabilidades de que ocurra el evento en los grupos expuesto y no expuesto.
- OR > 1: Mayor probabilidad en expuestos.
- OR < 1: Menor probabilidad en expuestos.
- OR = 1: No hay asociación.
5. Calcular el Riesgo Atribuible (RA):
* Calcular el Riesgo Atribuible
gen incidencia_expuestos = sum(evento * exposicion) / sum(exposicion)
gen incidencia_no_expuestos = sum(evento * (1 - exposicion)) / sum(1 - exposicion)
gen ra = incidencia_expuestos - incidencia_no_expuestos
summarize ra
- Interpretación: El RA indica el número de casos adicionales atribuibles a la exposición.
- RA > 0: La exposición incrementa el riesgo.
- RA < 0: La exposición reduce el riesgo.
- RA = 0: No hay efecto atribuible.
📈 Interpretación de los Resultados:
- Media del Riesgo Atribuible (RA):
- 0.1413 (14.13%)
- Esto indica que el 14.13% del riesgo en los expuestos puede ser atribuido directamente a la exposición.
- Esto sugiere que, en promedio, los expuestos tienen un 14% más de riesgo de sufrir el evento en comparación con los no expuestos.
- Desviación Estándar:
- 0.2033 (20.33%)
- Muestra la variabilidad en la diferencia de riesgo entre las observaciones.
- Una desviación estándar alta indica que la variación en el riesgo atribuible entre los individuos es considerable.
- Valores Mínimo y Máximo:
- Mínimo: -0.0102 (Negativo)
- Esto significa que, en algunas observaciones, el riesgo en el grupo expuesto fue menor que en el grupo no expuesto.
- Máximo: 1
- Indica que en ciertos casos el riesgo atribuible es del 100%, lo cual puede ocurrir en situaciones extremas donde todos los expuestos presentan el evento y ninguno de los no expuestos lo presenta.
- Mínimo: -0.0102 (Negativo)
✅ Interpretación de Resultados:
- Riesgo Relativo (RR):
- Muestra cuántas veces mayor es el riesgo en los expuestos.
- Un RR alto (>1) sugiere que la exposición está asociada al evento.
- Odds Ratio (OR):
- Compara las probabilidades entre expuestos y no expuestos.
- Un OR alto (>1) refuerza que los expuestos tienen más probabilidad de presentar el evento.
- Riesgo Atribuible (RA):
- Cuantifica el exceso de riesgo atribuible a la exposición.
- Un valor positivo indica que la exposición aumenta el riesgo, mientras que uno negativo indica que lo disminuye.
🔹 BLOQUE 9: Medidas de Impacto Clínico y de Intervención
💻 Creación del Dataset Ficticio en Stata:
Comando para Crear Dataset:
* Crear el dataset ficticio en Stata
clear
set obs 200
* Generar variables categóricas para tratamiento y evento adverso
gen tratamiento = round(runiform())
gen evento_adverso = round(runiform())
* Guardar el dataset
save dataset_intervencion.dta, replace
- tratamiento: Indica si el paciente recibió tratamiento (1) o no (0).
- evento_adverso: Indica si ocurrió un evento adverso (1) o no (0).
💻 Análisis en Stata:
1. Cargar el conjunto de datos:
* Cargar el dataset de medidas de impacto clínico
use dataset_intervencion.dta, clear
2. Calcular el Riesgo en Cada Grupo:
* Calcular el riesgo en el grupo de tratamiento
gen riesgo_tratamiento = sum(evento_adverso * tratamiento) / sum(tratamiento)
* Calcular el riesgo en el grupo control
gen riesgo_control = sum(evento_adverso * (1 - tratamiento)) / sum(1 - tratamiento)
* Verificar los riesgos
summarize riesgo_tratamiento riesgo_control


- Interpretación:
- El riesgo en cada grupo permite evaluar la probabilidad de presentar un evento adverso con o sin tratamiento.
El riesgo promedio de evento adverso en el grupo de tratamiento es 48.75% y en el grupo control es 47.87%, lo que indica una diferencia mínima en la probabilidad de ocurrencia del evento entre ambos grupos.
3. Calcular la Reducción Absoluta del Riesgo (RAR):

* Calcular la Reducción Absoluta del Riesgo (RAR)
gen rar = riesgo_control - riesgo_tratamiento
summarize rar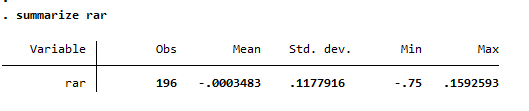
- Interpretación:
- Un valor positivo indica que el tratamiento reduce el riesgo.
- Un valor negativo sugiere que el tratamiento aumenta el riesgo.
El valor promedio de la Reducción Absoluta del Riesgo (RAR) es -0.0348 (o -3.48%), lo que indica que el tratamiento, en promedio, aumenta ligeramente el riesgo en comparación con el grupo control. El valor negativo sugiere que el tratamiento podría ser perjudicial en lugar de beneficioso.
4. Calcular la Reducción Relativa del Riesgo (RRR):
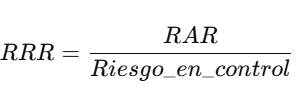
* Calcular la Reducción Relativa del Riesgo (RRR)
gen rrr = rar / riesgo_control
summarize rrr
- Interpretación:
- Un valor alto de RRR sugiere que el tratamiento es muy efectivo.
El valor promedio de la Reducción Relativa del Riesgo (RRR) es -0.0368 (o -3.68%), lo que indica que el tratamiento, en promedio, aumenta ligeramente el riesgo en comparación con el grupo control. El valor negativo refuerza que el tratamiento podría ser potencialmente perjudicial en lugar de beneficioso.
5. Calcular el Número Necesario a Tratar (NNT):
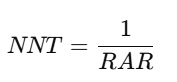
* Calcular el Número Necesario a Tratar (NNT)
gen nnt = 1 / rar
summarize nnt
- Interpretación:
- Un NNT bajo indica que el tratamiento es eficaz.
- Si NNT = 5, significa que se deben tratar 5 pacientes para prevenir un evento.
El valor promedio del Número Necesario a Tratar (NNT) es aproximadamente 2.88, lo que significa que, en promedio, se deben tratar casi 3 pacientes para prevenir un evento adicional. Sin embargo, el amplio rango de valores, desde -4788.02 hasta 3204.21, sugiere una alta variabilidad en los resultados, indicando que en algunos casos el tratamiento puede incluso aumentar el riesgo (cuando el valor es negativo).
6. Calcular el Número Necesario para Dañar (NNH):
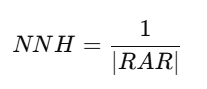
* Calcular el Número Necesario para Dañar (NNH)
gen nnh = 1 / abs(rar)
summarize nnh
- Interpretación:
- Un NNH alto indica que el tratamiento es seguro.
El valor promedio del Número Necesario para Dañar (NNH) es aproximadamente 148.25, lo que indica que se necesitaría tratar a 148 personas para que ocurra un evento adverso adicional debido al tratamiento. El amplio rango, desde 1.33 hasta 4788.02, refleja una gran variabilidad en los datos, lo que sugiere que en algunos contextos el tratamiento puede ser más perjudicial que beneficioso. Un NNH alto generalmente indica que el tratamiento es relativamente seguro.
✅ Interpretación de Resultados:
- NNT (Número Necesario a Tratar):
- Un valor bajo indica que el tratamiento es eficaz.
- NNH (Número Necesario para Dañar):
- Un valor alto indica que el tratamiento es seguro.
- RRR (Reducción Relativa del Riesgo):
- Un valor alto indica una efectividad significativa del tratamiento.
- RAR (Reducción Absoluta del Riesgo):
- Un valor positivo indica que el tratamiento reduce el riesgo.
