
SEMANA 1 – Introducción a la Epidemiología Clínica y R (24/03)
Lenguaje R
¿Qué es R?
R es un lenguaje de programación y entorno de software especializado en el análisis estadístico y la visualización de datos. Fue desarrollado originalmente para la investigación en estadística, pero ha crecido en popularidad en diversos campos, incluyendo la epidemiología.
Algunas de sus características principales incluyen:
✅ Un lenguaje de código abierto y gratuito.
✅ Un ecosistema con miles de paquetes especializados.
✅ Potentes herramientas para análisis de datos, modelado estadístico y visualización gráfica.
✅ Uso extensivo en salud pública, biomedicina e investigación clínica.
¿Por qué usar R en Epidemiología?
R es una herramienta fundamental en epidemiología porque permite:
📊 Manejo de datos: Procesar grandes volúmenes de información, como registros hospitalarios o bases de datos epidemiológicas.
📈 Análisis estadístico: Calcular tasas de incidencia, prevalencia, razones de riesgo (RR), odds ratio (OR), regresión logística, entre otros.
📉 Visualización de datos: Crear gráficos epidemiológicos como curvas epidémicas, mapas de calor y gráficos de tendencias.
📚 Reproducibilidad: Facilita la creación de análisis reproducibles y reportes científicos.
Importancia de R en Salud y Epidemiología
El uso de R en la investigación biomédica y en salud pública se ha incrementado debido a su capacidad para manejar grandes volúmenes de datos y realizar análisis estadísticos reproducibles. Algunas aplicaciones clave incluyen:
✅ Epidemiología: Modelado de enfermedades, estudios de cohorte, análisis de casos y controles.
✅ Bioestadística: Regresión logística, análisis de supervivencia, pruebas de hipótesis.
✅ Salud Pública: Análisis de tendencias de enfermedades, evaluación de impacto de políticas de salud.
✅ Medicina Basada en Evidencia: Meta-análisis, revisiones sistemáticas.
R vs. Otros Lenguajes de Programación
| Característica | R | Python | SPSS | Stata |
|---|---|---|---|---|
| Código Abierto | ✅ | ✅ | ❌ | ❌ |
| Facilidad de Uso | Media | Media | Alta | Alta |
| Análisis Estadístico | Avanzado | Medio | Alto | Alto |
| Manejo de Grandes Datos | Medio | Alto | Medio | Medio |
| Visualización de Datos | Excelente | Buena | Limitada | Limitada |
📌 Conclusión: R es ideal cuando el enfoque principal es el análisis estadístico y la visualización de datos, especialmente en el ámbito de la salud.
Componentes de R
A) Consola de R
- Permite ejecutar comandos de manera interactiva.
B) RStudio
- Interfaz gráfica para R que facilita la escritura de código y la gestión de proyectos.
C) Paquetes en R
R tiene una gran cantidad de paquetes que extienden sus capacidades. Algunos importantes en salud:
- tidyverse: Manipulación y limpieza de datos.
- ggplot2: Visualización de datos.
- survival: Modelos de análisis de supervivencia.
- epitools: Análisis epidemiológico.
- caret: Machine Learning aplicado a salud.
Flujo de Trabajo en R
1️⃣ Importación de datos: Leer archivos CSV, Excel, bases SQL, etc.
2️⃣ Exploración de datos: Identificar valores faltantes, distribución de variables.
3️⃣ Transformación y limpieza: Manejo de datos perdidos, filtrado de datos irrelevantes.
4️⃣ Análisis estadístico: Medidas descriptivas, inferencia estadística, regresiones.
5️⃣ Visualización: Creación de gráficos para interpretar resultados.
6️⃣ Exportación de resultados: Generar reportes en PDF, Word o Excel.
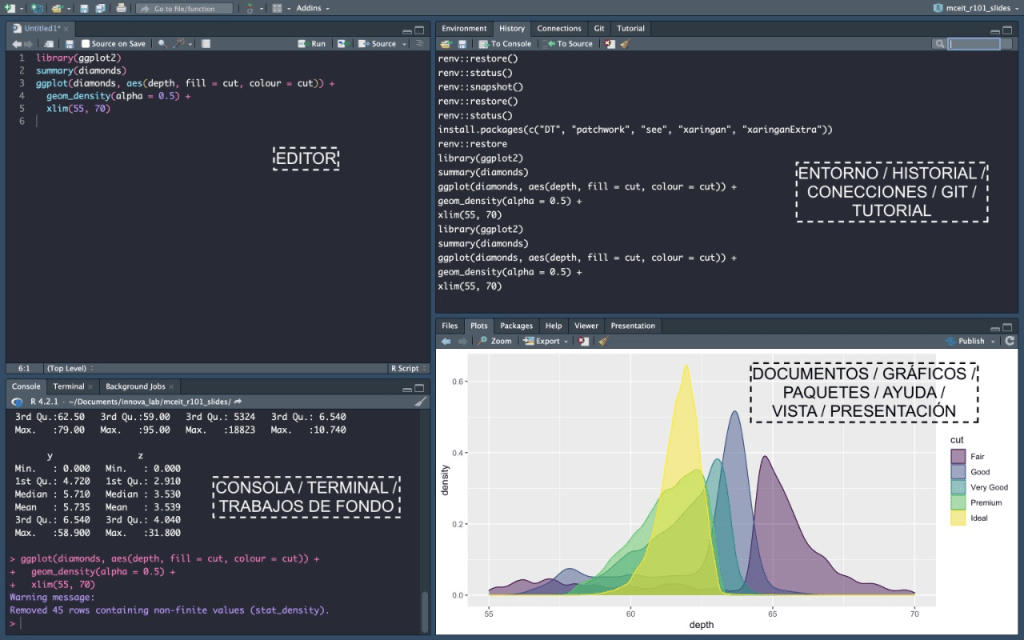
Entorno básico
El entorno inicial de RStudio consiste en 4 paneles:
- Editor (Soruce): Donde podemos escribir nuestros códigos en
scripts
Permite escribir y guardar código en archivos con extensión.R. Se ejecutan líneas específicas o todo el script conCtrl + Enter. - Consola (Console): Donde se conecta RStudio con R.
Lugar donde se ejecutan los comandos en tiempo real. Se pueden escribir líneas de código y ver los resultados directamente. - Entorno (Environment): Donde podemos explorar los elementos que hemos cargado en R. En este panel también podemos visualizar la historia de códigos y conexiones entre otros.
- Salidas (Files): Donde podemos ver los gráficos y otras salidas de nuestro código. También hay pestañas para ver los archivos, los paquetes, la ayuda de funciones y visor de otros elementos web.
Tipos de Objetos en R
Variables y Asignación
En R, las variables se crean con <- o =:
<- 10
b = 20
c <- a + b
print(c) # Resultado: 30
Tipos de Datos Básicos

Estructuras de Datos
📌 Vectores (una dimensión):
edades <- c(25, 30, 40, 50)
📌 Matrices (dos dimensiones):
m <- matrix(1:9, nrow=3, ncol=3)
📌 Data Frames (conjunto de datos tipo tabla):
pacientes <- data.frame(ID = 1:3, Nombre = c("Ana", "Luis", "Carlos"), Edad = c(25, 40, 35))
Instalación y Uso de Paquetes
🔹 Instalar paquetes
install.packages("ggplot2")
🔹 Cargar un paquete
library(ggplot2)
🔹 Ver paquetes instalados
installed.packages()
Funcionamiento básico
Aritmética Básica
# Suma
2 + 3 # Resultado: 5
# Resta
10 – 4 # Resultado: 6
# Multiplicación
5 * 6 # Resultado: 30
# División
8 / 2 # Resultado: 4
# Potencia
3^2 # Resultado: 9
# Raíz cuadrada
sqrt(16) # Resultado: 4
# Módulo (residuo de la división)
10 %% 3 # Resultado: 1
# Cociente entero
10 %/% 3 # Resultado: 3
Asignación de Variables
x <- 5
y <- 10
z <- x + y # Resultado: 15
Operaciones con Vectores
v1 <- c(1, 2, 3)
v2 <- c(4, 5, 6)
# Suma de vectores
v1 + v2 # Resultado: 5 7 9
# Producto por escalar
v1 * 2 # Resultado: 2 4 6
# Producto elemento a elemento
v1 * v2 # Resultado: 4 10 18
Funciones Básicas
mean(c(1, 2, 3, 4, 5)) # Media: 3
sum(c(1, 2, 3)) # Suma: 6
length(c(1, 2, 3)) # Longitud: 3
Medidas de tendencia central y dispersión
Creación de un Dataset Simulado: Datos simulados de casos diarios de una enfermedad
casos_diarios <- c(5, 8, 10, 15, 20, 20, 25, 30, 30, 30, 35, 40)
Media (Promedio)
media_casos <- mean(casos_diarios)
print(media_casos) # Promedio de casos diarios
Mediana
mediana_casos <- median(casos_diarios)
print(mediana_casos) # Mediana de casos diarios
Moda
moda <- function(x) {
unique_x <- unique(x) # Valores únicos
frec_x <- tabulate(match(x, unique_x)) # Frecuencia de cada valor
unique_x[which.max(frec_x)] # Retorna el valor más frecuente
}
moda_casos <- moda(casos_diarios)
print(moda_casos) # Moda de los casos diarios
Rango
rango_casos <- range(casos_diarios)
print(rango_casos) # Muestra el valor mínimo y máximo
Varianza
varianza_casos <- var(casos_diarios)
print(varianza_casos) # Varianza de los casos diarios
Desviación Estándar
desviacion_estandar_casos <- sd(casos_diarios)
print(desviacion_estandar_casos) # Desviación estándar
Coeficiente de Variación
coef_variacion <- (sd(casos_diarios) / mean(casos_diarios)) * 100
print(coef_variacion) # Coeficiente de variación en porcentaje
Cuartiles y Percentiles
cuartiles_casos <- quantile(casos_diarios, probs = c(0.25, 0.5, 0.75))
print(cuartiles_casos) # Muestra Q1, Q2 (mediana) y Q3
percentil_90 <- quantile(casos_diarios, probs = 0.90)
print(percentil_90) # Percentil 90 de los casos diarios
Resumen general
summary(casos_diarios) # Muestra mínimo, Q1, mediana, media, Q3 y máximo
Tidyverse
tidyverse es una colección de paquetes de R diseñados para la ciencia de datos. Todos estos paquetes comparten la misma filosofía, por lo que aplican las mismas reglas de sintaxis sobre todos estos paquetes.
Existe más de 25 paquetes dentro del tidyverse y conforman un ecosistema para importar, estructurar, visualizar, modelar y comunicar datos.
Estos paquetes pueden ser cargados de forma individual. Sin embargo, el paquete tidyverse permite cargar 9 paquetes considerados el core de tidyverse:

Instalación y Carga de Tidyverse
Antes de usar Tidyverse, es necesario instalarlo y cargarlo en el entorno de R:
install.packages(«tidyverse») # Instalación
library(tidyverse) # Carga del paquete
Para verificar qué paquetes del Tidyverse están instalados y cargados:
tidyverse_packages() # Lista de paquetes incluidos
tidyverse_update() # Actualizar paquetes
Conceptos Teóricos de los Paquetes del Tidyverse
1️⃣ dplyr – Manipulación de Datos
Versión en la imagen: 1.1.0.9000
📌 Descripción:dplyr es el paquete principal de manipulación de datos en Tidyverse. Facilita la transformación de datos mediante una sintaxis clara basada en verbos.
📌 Funciones principales:
filter()→ Filtrar filas según condiciones.select()→ Seleccionar columnas específicas.mutate()→ Crear o modificar variables.arrange()→ Ordenar los datos.group_by()→ Agrupar datos por categorías.summarise()→ Generar estadísticas resumen.
2️⃣ forcats – Manejo de Variables Categóricas (Factores)
Versión en la imagen: 1.0.0
📌 Descripción:forcats está diseñado para manejar factores en R, que representan variables categóricas. Los factores son útiles en análisis epidemiológicos cuando trabajamos con categorías como sexo, grupo sanguíneo, o diagnóstico clínico.
📌 Funciones principales:
fct_reorder()→ Reordenar niveles de factores.fct_lump()→ Agrupar categorías poco frecuentes en «Otros».fct_rev()→ Invertir el orden de los niveles.
3️⃣ ggplot2 – Visualización de Datos
Versión en la imagen: 3.4.1
📌 Descripción:ggplot2 es el paquete más potente y flexible para la visualización de datos en R. Permite generar gráficos personalizados mediante una sintaxis basada en capas.
📌 Componentes principales:
aes()→ Define mapeos estéticos (ejes x, y, color, tamaño).geom_*()→ Tipos de gráficos (barras, líneas, puntos, boxplots).facet_*()→ Facetas para dividir datos en múltiples gráficos.
4️⃣ lubridate – Manejo de Fechas y Tiempos
Versión en la imagen: 1.9.2
📌 Descripción:lubridate simplifica el manejo de fechas y horas en R, lo cual es crucial en estudios epidemiológicos y análisis de cohortes con seguimiento en el tiempo.
📌 Funciones principales:
ymd(), dmy(), mdy()→ Convertir texto en fechas.year(), month(), day()→ Extraer componentes de fechas.interval()→ Calcular intervalos de tiempo.
5️⃣ purrr – Programación Funcional y Manejo de Listas
Versión en la imagen: 1.0.1
📌 Descripción:purrr permite aplicar funciones a estructuras de datos (vectores, listas, data frames) de forma eficiente y sin necesidad de bucles for.
📌 Funciones principales:
map()→ Aplica una función a cada elemento de una lista o vector.map_df()→ Devuelve un data frame en vez de una lista.pmap()→ Aplica funciones a múltiples listas.
6️⃣ readr – Importación de Datos
Versión en la imagen: 2.1.4
📌 Descripción:readr permite importar archivos de datos de forma más rápida y eficiente que la función base read.csv().
📌 Funciones principales:
read_csv()→ Cargar archivos CSV.read_tsv()→ Cargar archivos delimitados por tabulaciones.write_csv()→ Guardar data frames en formato CSV.
7️⃣ stringr – Manipulación de Cadenas de Texto
Versión en la imagen: 1.5.0
📌 Descripción:stringr facilita el trabajo con textos, como limpiar nombres de pacientes, normalizar datos categóricos o extraer información específica de strings.
📌 Funciones principales:
str_detect()→ Detectar patrones en textos.str_replace()→ Reemplazar partes de un string.str_sub()→ Extraer partes de un string.
8️⃣ tibble – Mejora en la Representación de Data Frames
Versión en la imagen: 3.1.8
📌 Descripción:tibble proporciona una versión mejorada de los data frames en R, optimizando la visualización y manipulación de datos.
📌 Diferencias con los data frames tradicionales:
- Más legible: No muestra demasiadas filas o columnas por defecto.
- No convierte caracteres en factores automáticamente.
- Compatible con
dplyry otros paquetes detidyverse.
9️⃣ tidyr – Transformación y Organización de Datos
Versión en la imagen: 1.3.0
📌 Descripción:tidyr se enfoca en estructurar los datos en el formato «tidy», es decir, que cada columna sea una variable y cada fila sea una observación.
📌 Funciones principales:
pivot_longer()→ Convertir datos anchos en largos.pivot_wider()→ Convertir datos largos en anchos.separate()→ Dividir una columna en múltiples.unite()→ Combinar múltiples columnas en una.
